上一章 文档首页 下一章
2.12.1 背景
为了应对产品海量用户的愿景需求,这里将设计一个分布式的数据库存储方案,以便能满足数据量的骤增、云服务的横向扩展、后台接口开发的兼容性,以及数据迁移等问题,避免日后因为全部数据都存放在单台服务器上的限制。
2.12.2 主要思想
- 1、分库分表
- 2、路由规则
- 3、扩展字段
- 4、可配置
- 5、SQL语句自动生成
(1)分库分表
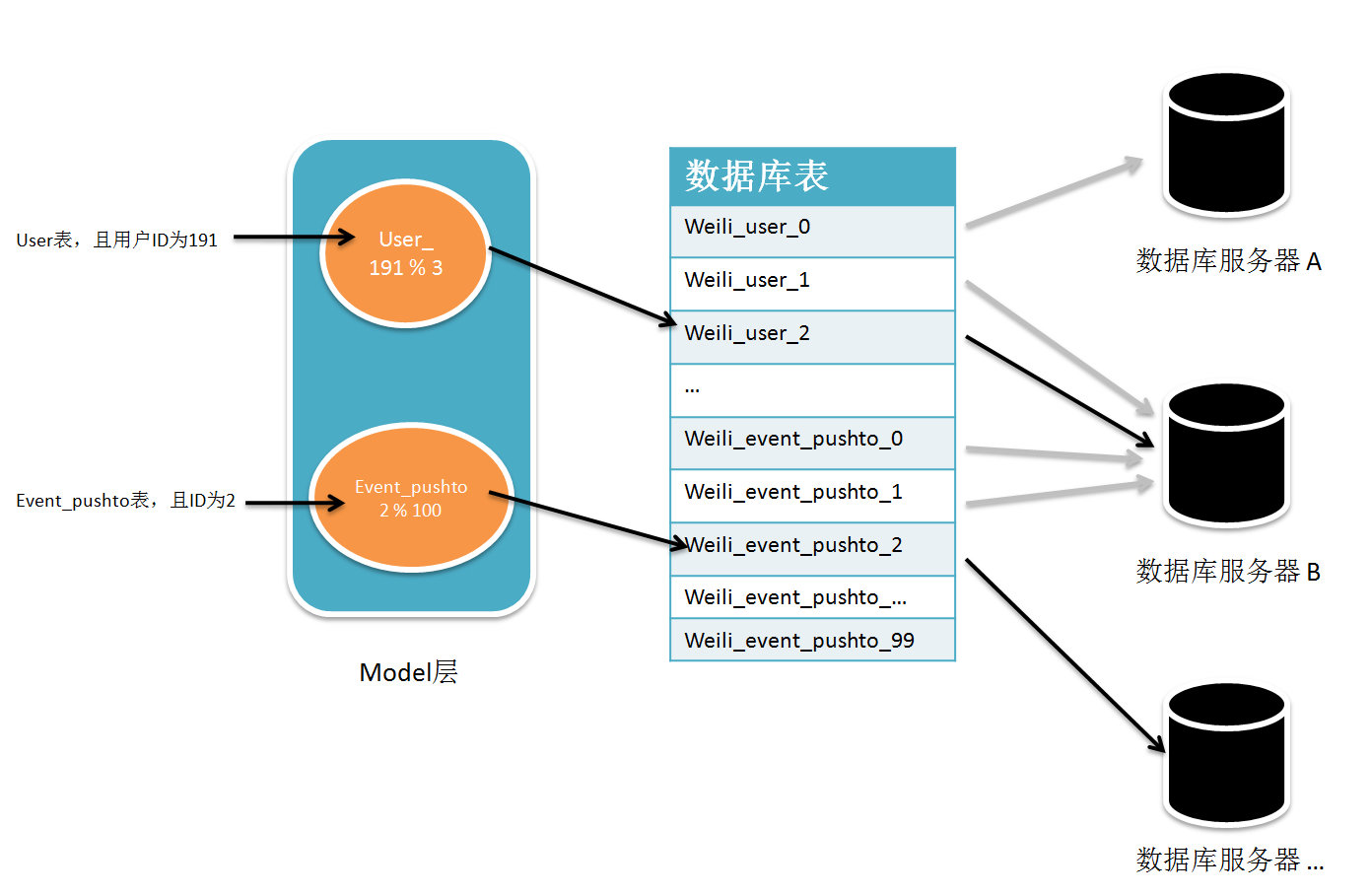
是指将不需要进行必要关联查询的表分开存放,如存放事件推送的weili_event_pushto和存放标签的weili_tag;同时,对于 同一个表,因为存放的数据量是可预见式的暴增,如上述的weili_event_pushto,每时每刻都会产生大量的来自用户发布的事件,因此为了突破 MySQL单表的限制以及其他问题,需要将此表同时创建N份。
(2)路由规则
在上面进行了分库分表后,开发人员在读取时,就需要根据相应的规则找到对应 的数据库和数据库表,这里建议每个表都需要有int(11)类型的id字段,以便作为分表的参考。
(3)扩展字段
在完成了分库分表和制定路由规则后,考虑到日后有数据库的DB变更,为减少DB变更对现有数据库表的影响,这里建议每个表都增加text类型的extra_data字段,并且使用json格式进行转换存储。
(4)可配置
在有了N台数据库服务器以及每个表都拆分成M张表后,为减少后台接口开发人员的压力,有必须在后台接口框架提供可配置 的支持。即:数据库的变更不应影响开发人员现有的开发,也不需要开发人员作出代码层面的改动,只需要稍微配置一下即可。关于这块,请见下面的框架实现部 分。
(5)SQL语句自动生成
对于相同表的建表语句,可以通过脚本来自动生成,然后直接导入数据即可。
2.12.3 PhalApi框架的实现方案
PhalApi框架主要需要实现的是路由这一层的映射,并且通过可配置的方式进行控制,同时还应支持生产环境和测试环境的异同,如在测试环境我们明显不需要1000张数据库的表。为此,需要提供一种 表名 + id 映射到 数据库服务器 + 具体哪张表 的规则。
2.12.4 使用示例
(1)配置数据库的路由配置
修改./Config/dbs.php文件,以下是参考的示例配置。其中servers为DB服务器,包括数据库的账号信息等,tables为数据库表的映射关系,其中default下标为缺省的数据库路由。
在每个数据库表里面,可以配置多个数据库表,通过开始的下标start和结束的下标end来对表进行分布式存放,并且如果没有start和end的,则视为不需要拆分存放,同时也是当找不到合适时的拆分表时所采用的默认配置。
return array(
/**
* avaiable db servers
*/
'servers' => array(
'db_demo' => array(
'host' => 'localhost', //数据库域名
'name' => 'test', //数据库名字
'user' => 'root', //数据库用户名
'password' => '123456', //数据库密码
'port' => '3306', //数据库端口
),
),
/**
* custom table map
*/
'tables' => array(
'__default__' => array(
'prefix' => 'tbl_',
'key' => 'id',
'map' => array(
array('db' => 'db_demo'),
),
),
'demo' => array(
'prefix' => 'tbl_',
'key' => 'id',
'map' => array(
array('db' => 'db_demo'),
array('start' => 0, 'end' => 2, 'db' => 'db_demo'),
),
),
),
);上面示例配置的意思是:
表名 DB服务器
tbl_demo db_demo
tbl_demo_0 db_demo
tbl_demo_1 db_demo
tbl_demo_2 db_demo(2)准备需要创建表的基本SQL语句
这里说的基本SQL语句是指:仅是这个表所特有的字段,排除已固定公共有的自增主键id,和扩展字段ext_data。下面是一个示例:
`name` varchar(11) DEFAULT NULL,(3)生成并导入SQL语句
由于拆分后的数据库表数量众多,这里提供了一个快捷的脚本工具来生成所需要创建的数据库表。
$ php ./build_sqls.php
Usage: ./build_sqls.php <dbs_config> <table> [engine=InnoDB]执行上面的脚本,输入数据库表参数后:
php ./build_sqls.php ./Config/dbs.php demo将会从配置文件 里面寻找所需要创建的表,并生成类似以下的SQL语句:
/**
* DB: localhost db_demo
*/
CREATE TABLE `demo` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(11) DEFAULT NULL,
`ext_data` text COMMENT 'json data here',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/**
* DB: localhost db_demo
*/
CREATE TABLE `tpl_demo_0` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(11) DEFAULT NULL,
`ext_data` text COMMENT 'json data here',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `tpl_demo_1` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(11) DEFAULT NULL,
`ext_data` text COMMENT 'json data here',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `tpl_demo_2` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(11) DEFAULT NULL,
`ext_data` text COMMENT 'json data here',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;(4)使用与代码开发
在将上面的SQL语句导入数据库后,即可以像之前那样操作数据库。下面是一些示例:
DI()->notorm = new PhalApi_DB_NotORM(PhalApi_DI::one()->config->get('dbs'), true);
DI()->notorm->demo->where('id', '1')->fetch();用到了拆分表的代码示例,假设demo表被拆分成了3个表,则客户端在调用里,需要根据(id % 3 )来拼接合适的数据库表名,其他使用不变。
DI()->notorm = new PhalApi_DB_NotORM(PhalApi_DI::one()->config->get('dbs'), true);
$row = DI()->notorm->demo_0->where('id', '3')->fetch();
$row = DI()->notorm->demo_1->where('id', '10')->fetch();
$row = DI()->notorm->demo_2->where('id', '2')->fetch();使用Model基类的情况
更好的写法,应该是继承于PhalApi_Model_NotORM,并统一实现分表的操作,如:
<?php
class Model_Demo extends PhalApi_Model_NotORM {
protected function getTableName($id) {
$tableName = 'demo';
if ($id !== null) {
$tableName .= '_' . ($id % 3);
}
return $tableName;
}
}然后,上面的查询分别对应:
$model = new Model_Demo();
$row = $model->get('3', 'id');
$row = $model->get('10', 'id');
$row = $model->get('2', 'id');更进一步,我们可以通过$this->getORM($id)来获取分表的实例进行分表的操作,如:
<?php
class Model_Demo extends PhalApi_Model_NotORM {
//... ...
public function getNameById($id) {
$row = $this->getORM($id)->select('name')->fetchRow(); //假设$id为3,则 $this->getORM($id) 等效于 DI()->notorm->demo_0
return !empty($row) ? $row['name'] : '';
}
}2.12.5 多个数据库的配置方式
当需要使用多个数据库时,可以先在servers中可以配置多组数据库的信息,然后在tables为不同的数据库表指定不同的数据库服务器。
假设我们有两台数据库服务器,分别叫做db_A、db_B,即:
return array(
/**
* DB数据库服务器集群
*/
'servers' => array(
'db_A' => array( //db_A
'host' => '192.168.0.1', //数据库域名
// ... ...
),
'db_B' => array( //db_B
'host' => '192.168.0.2', //数据库域名
// ... ...
),
),
//... ...若db_A服务器中的数据库有表a_table_user、a_table_friends,而db_B服务器中的数据库有表b_table_article、b_table_comments,则:
<?php
return array(
//... ...
/**
* 自定义路由表
*/
'tables' => array(
//通用路由
'__default__' => array(
'prefix' => 'a_', //以 a_ 为表前缀
'key' => 'id',
'map' => array(
array('db' => 'db_A'), //默认,使用db_A数据库
),
),
'table_article' => array( //表b_table_article
'prefix' => 'b_', //表名前缀
'key' => 'id', //表主键名
'map' => array( //表路由配置
array('db' => 'db_B'), // b_table_article表使用db_B数据库
),
),
'table_comments' => array( //表b_table_article
'prefix' => 'b_', //表名前缀
'key' => 'id', //表主键名
'map' => array( //表路由配置
array('db' => 'db_B'), // b_table_comments表使用db_B数据库
),
),
),
如果项目存在分表的情况,可结合上述的分表的说明进行配置。
这里为了让大家更为明了,假设db_A服务器中的数据库有表a_table_user、a_table_friends_0到a_table_friends_9(共10张表),
而db_B服务器中的数据库有表b_table_article、b_table_comments_0到b_table_comments_19(共20张表),则结合起来的完整配置为:
<?php
return array(
/**
* DB数据库服务器集群
*/
'servers' => array(
'db_A' => array( //db_A
'host' => '192.168.0.1', //数据库域名
// ... ...
),
'db_B' => array( //db_B
'host' => '192.168.0.2', //数据库域名
// ... ...
),
),
/**
* 自定义路由表
*/
'tables' => array(
//通用路由
'__default__' => array(
'prefix' => 'a_', //以 a_ 为表前缀
'key' => 'id',
'map' => array(
array('db' => 'db_A'), //默认,使用db_A数据库
),
),
'table_friends' => array( //分表配置
'prefix' => 'a_', //表名前缀
'key' => 'id', //表主键名
'map' => array( //表路由配置
array('db' => 'db_A'), // b_table_comments表使用db_B数据库
array('start' => 0, 'end' => 9, 'db' => 'db_A'), //分表配置(共10张表)
),
),
'table_article' => array( //表b_table_article
'prefix' => 'b_', //表名前缀
'key' => 'id', //表主键名
'map' => array( //表路由配置
array('db' => 'db_B'), // b_table_article表使用db_B数据库
),
),
'table_comments' => array( //表b_table_article
'prefix' => 'b_', //表名前缀
'key' => 'id', //表主键名
'map' => array( //表路由配置
array('db' => 'db_B'), // b_table_comments表使用db_B数据库
array('start' => 0, 'end' => 19, 'db' => 'db_B'), //分表配置(共20张表)
),
),
),
);2.12.6 与主从数据库的有机结合
虽然这是专门为海量数据设计的存储方案,但也是可以结合主从配置来获得更庞大强壮的方案,当然为之付出的是复杂性的引入。
简单地,可以将dbs.php复制一份dbs_slave.php出来给从库使用,然后注册一个从库的服务:
DI()->slaveNotorm = new PhalApi_DB_NotORM(DI()->config->get('slave_dbs'));最后,在需要使用从库来读取时,使用slaveNotorm 服务即可。
2.12.7 不足与注意点
这样的设计是有明显的灵活性的,因为在后期如果需要迁移数据库服务器,我们可以在框架支持的情况下轻松应对,但依然需要考虑到一些问题和不足。
(1)DB变更
DB变更,这块是必不可少的,但一旦数据库表被拆分后,表数量的骤增导致变更执行困难,所以这里暂时使用了一个折中的方案,即提供了一个ext_data 扩展字段用于存放后期可能需要的字段信息,建议采用json格式,因为通用且长度比序列化的短。但各开发可以根据自己的需要决定格式。即使如此,扩展字段 明显做不到一些SQL的查询及其他操作。
(2)表之间的关联查询
表之间的关联查询,这个是分拆后的最大问题。虽然这样的代价是我们可以得到更庞大的存储设计, 而且很多表之间不需要必须的关联的查询,即使我们需要,我们也可以通过其他手段如缓存和分开查询来实现。这对开发人员有一定的约束,但是对于可预见性的海 量数量,这又是必须的。





