
我们能够有意识地推断我们想要在哪一条想法的溪流中遨游,然而此后与那些想法的接触会潜在地塑造我们的习惯和信仰。 -- 《智慧社会》
1.27.1 写在前面的话
此篇章有点长,但我认为是值得一读的。因为这里我将逐步讲述如何在已有的基础上演变扩展出更高层次的代码结构和系统架构,而不致于因目前频繁的需求变更而导致代码凌乱不堪。更为重要的是,你将能从中发现,如何在一个框架中持续演变,最终体验浮现式设计的乐趣。如果你的项目亦能如此,我相信你会找到编程如同搭建积木般轻便明了的感觉。
1.27.2 更富表现力的Model层
接口不尽相同,主要区别在于领域业务数据的处理。而数据的来源则更为广泛,可能是来自数据库,可能来自第三方平台接口,可能存放于内存。所以,PhalApi这里的Model层,则是 广义上的数据源层 ,用于获取原始的业务数据,而不管来自何方,何种存储媒介。这也是为什么我们没有将Model层打造成活动纪录或者数据映射器的原因。当然,如果你确实需要,也可以自行调整。
如果数据来源于数据库,我们则需要考虑到数据库服务器的感受,保证不会有过载的请求而导致它罢工。对此,我们可以结合缓存来进行性能优化。
如,一般地:
// 版本1:简单的获取
$model = new Model_User();
$rs = $model->getByUserId($userId);这种是没有缓存的情况,当发现有性能问题并且可以通过缓存来解决时,我们可以在调用时简单引入缓存:
// 版本2:使用单点缓存/多级缓存 (应该移至Model层中)
$key = 'userbaseinfo_' . $userId;
$rs = DI()->cache->get($key);
if ($rs === NULL) {
$rs = $model->getByUserId($userId);
DI()->cache->set($key, $rs, 600);
}但不建议在领域Domain层中引入缓存,因为会导致混淆和不便进行测试。更好是将缓存的处理移至Model,保持数据获取的透明性:
class Model_User extends PhalApi_Model_NotORM {
public function getByUserIdWithCache($userId) {
$key = 'userbaseinfo_' . $userId;
$rs = DI()->cache->get($key);
if ($rs === NULL) {
$rs = $this->getByUserId($userId);
DI()->cache->set($key, $rs, 600);
}
return $rs;
}对应地,外部的调用调整成:
// 版本3:使用单点缓存/多级缓存
$model = new Model_User();
$rs = $model->getByUserIdWithCache($userId);至此,Model层对于上层如Domain来说,负责获取源数据,而不管此数据来自于数据库,还是远程接口,抑或是缓存包装下的数据。这正是我们使用数组在Model层和Domain层通讯的原因,因为数组更加通用,不需要额外添加实体。
1.27.3 重量级数据获取的应对方案
纵使更富表现力的Model很好地封装了源数据的获取,但是仍然会遇到一些尴尬的问题。特别地,当我们大量地进行缓存读取判断时,会出现很多重复的代码,这样既不雅观也难以管理,甚至会出现一些简单的人为编写错误而导致的BUG。另外,当我们需要进行预览、调试或测试时,我们是不希望看到缓存的,即我们能够手工指定是否需要缓存。
这里再稍微简单回顾总结一下我们现在的问题:我们希望通过缓存策略来优化Model层的源数据获取,特别当源数据获取的成本非常大时。但我们又希望我们可以轻易控制何时需要缓存,何时不需要,并且希望原有的代码能在OCP的原则下不需要修改,但又能很好地传递源数据获取的复杂参数。归纳一下,则可分为三点:缓存的控制、源数据的获取、复杂参数的传递。
(1)缓存的控制
不管是单点缓存,还是多级缓存,都希望使用原有已经注册的cache组件服务。所以,应该使用委托。委托的另一个好处在于使用外部依赖注入可以获得更好的测试性。
(2)源数据的获取
源数据的获取,作为源数据获取的主要过程和主要实现,需要进行缓存的控制(可细分为:是否允许读缓存、和是否允许写缓存)、 获取缓存的key值和有效时间,以及最终原始数据的获取。明显,这里应该使用模板方法,然后提供钩子函数给具体子类。
这里,我们提供了Model代理抽象类PhalApi_ModelProxy。
之所以使用代理模式,是因为实际上并不一定会真正调用到最终源数据的获取,因为往往源数据的获取成本非常高,故而我们希望通过缓存来拦截数据的获取。
由于Model代理被上层的Domain领域层调用,但又依赖于下层Model层获得原始数据,所以处于Domain和Model之间。为了保持良好的项目代码层级,如果需要创建PhalApi_ModelProxy子类,建议新建一个ModelProxy目录。
如对用户基本信息的获取,我们添加了一个代理:
class ModelProxy_UserBaseInfo extends PhalApi_ModelProxy {
protected function doGetData($query) {
$model = new Model_User();
return $model->getByUserId($query->id);
}
protected function getKey($query) {
return 'userbaseinfo_' . $query->id;
}
protected function getExpire($query) {
return 600;
}
}其中,doGetData($query)方法由具体子类实现,委托给Model_User的实例进行源数据获取。另外,实现钩子函数以返回缓存唯一key,和缓存的有效时间。
这里只是作为简单的示例,更好的建议是应该将缓存的时间纳入配置中管理,如 配置四个缓存级别:低(5 min)、中(10 min)、高(30 min)、超(1 h) ,然后根据不同的业务数据使用不同的缓存级别。这样,即便于团队交流,也便于缓存时间的统一调整。
(3)复杂参数的传递
敏锐的读者会发现,上面有一个$query查询对象,这就是我们即将谈到的复杂参数的传递。
$query是查询对象PhalApi_ModelQuery的实例。我们强烈建议此类实例应当被作为 值对象 对待。虽然我们出于便利将此类对象设计成了结构化的使用。但你可以轻松通过new PhalApi_ModelQuery($query->toArray())来拷贝一个新的查询对象。
此查询对象,目前包括了四个成员变量:是否读缓存、 是否写缓存、主键id、时间戳。
很多时候,这四个基本的变量是满足不了各项目的实际需求的,因此你可以定义你的查询子类, 以支持丰富的数据获取。如调用优酷平台接口获取用户最近上传发布的视频时,需要用户昵称、获取的数量、排序种类等。
(4)最终的调用
在完成了上面的工作后,让我们看下最终呈现的效果:
// 版本3:缓存 + 代理
$query = new PhalApi_ModelQuery();
$query->id = $userId;
$modelProxy = new ModelProxy_UserBaseInfo();
$rs = $modelProxy->getData($query);在领域层中,我们切换到了Model代理获取数据,而不再是原来的Model直接获取。其中新增的是代理具体类 ModelProxy_UserBaseInfo,和可选的查询类。
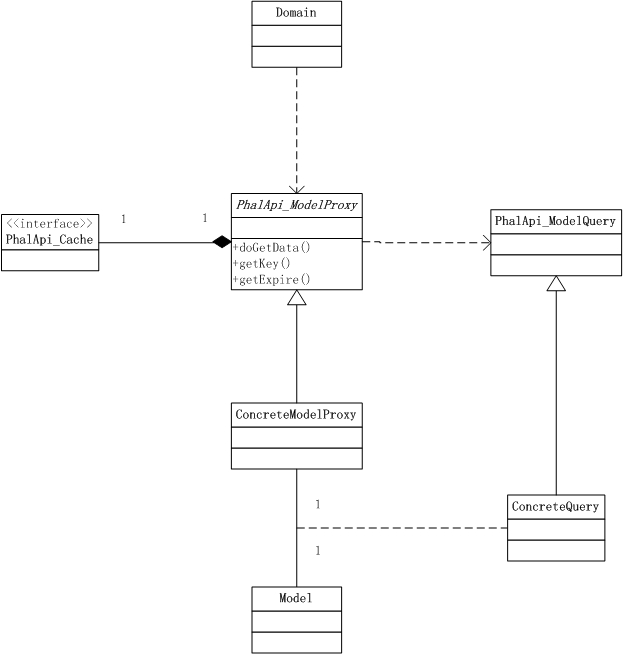
(5)UML静态图
至此,我们很好地在源数据的获取基础上,统一结合缓存策略。你会发现: 缓存节点可变、具体的源数据可变、复杂的查询亦可变 。
将此图简化一下,可得到:
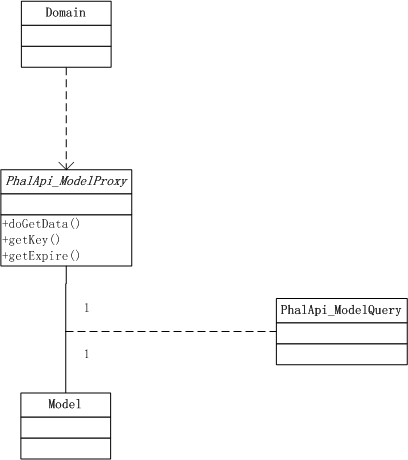
这样的设计是合理的,因为缓存节点我们希望能在项目内共享,而不管是哪块的业务数据;对于具体的源数据获取明显也是不尽相同,所以也需要各自实现,同时对于同一类业务数据(如用户基本信息)则使用一样的缓存有效时间和指定格式的缓存key(通常结合不同的id组成唯一key);最后在前面的缓存共享和同类数据的基础上,还需要支持不同数据的具体获取,因此需要查询对象。也就是说,你可以在不同的层级不同的范畴内进行自由的控制和定制。
如果退回到最初的版本,我们可以对比发现,Model Proxy就是Domain和Model间的桥梁,即:中间层。因为每次直接通过Model获取源数据的成本较大,我们可以通过Model Proxy模型代理来缓存获取的数据来减轻服务器的压力。

1.27.4 细粒度和可测试性
这无疑是细粒度的划分,但对于支撑复杂的领域业务却发挥着重要的作用。一来是如此清楚明了,二来则是带来了可测试性。
正如前面提及到的,我们在预览、调试、单元测试或者后台计划任务时,不希望有缓存的干扰。在细粒度划分的基础上,可轻松用以下方法实现而不必担心会破坏代码的简洁性。
(1)取消缓存的方法1: 外部注入模拟缓存
在构造Model代理时,默认情况下使用了DI()->cache作为缓存,当需要进行单元测试时,我们可以两种途径在外部注入模拟的缓存而达到测试的目的:替换全局的DI()->cache,或单次构造注入。对于计划任务则可以在统一的后台任务启动文件将DI()->cache设置成空对象。
(2)取消缓存的方法2: 查询中的缓存控制
在项目层次,我们可以统一构造自己的查询基类,以实现对缓存的控制。
如:
class Common_ModelQuery extends PhalApi_ModelQuery {
public function __construct($queryArr = array()) {
parent::__construct($queryArr);
if (DI()->debug) {
$this->readCache = FALSE;
$this->writeCache = FALSE;
}
}
}至于DI()->debug的设置,则可以在入口文件中根据约定的接口参数设定,简单地如:
if (isset($_GET['debug']) && $_GET['debug'] == 1) {
DI()->debug = true;
}这样便可以获得了接口预览和调试的能力。
1.27.5 何时使用此方案?
可以看到,此方案是在缓存策略(包括单点缓存、低高速缓存、多级缓存)和广义Model层基础上扩展的,以便应对重量级的业务数据获取。此方案有一定的优势,但作为代价则是额外的代码编写以及层级复杂性。并且,我们还没谈及到数据变更时的处理。
所以,请在确切需要统一封装高成本的数据获取时,才使用此方案。
1.27.6 扩展:多接口参数传递的优雅处理方案
当接口的查询参数过多时,我们需要手工重复地将接口参数从Api层传递到Domain层,再通过Query对象传递到Model层,这中间任何一个环节的缺失或遗漏都会造成一个BUG。
为此,项目可以考虑使用一种更为优雅的方案来进行整合,并实现自动化参数获取,但又保留接口原来的参数验证。
假设,我们需要以下多个接口参数:
function getRules() {
return array(
'getList' => array(
'keyword' => array(...),
'filed' => array(...),
'page' => array(...),
'perpage' => array(...),
'order' => array(...),
),
);
} 为避免出现以下这样的手工调用(而且也不符合值对象的特征):
$query = new Query_Demo();
$query->keyword = $this->keyword;
$query->filed = $this->filed;
$query->page = $this->page;
$query->perpage = $this->perpage;
$query->order = $this->order;
$domain = new Domain_Demo();
$list = $domain->getList($query);我们首先需要提取出一个层超类:
class Query_Demo extends PhalApi_ModelQuery {
public $keyWord;
public $filed;
public $page;
public $perpage;
public $order;
public function __construct($api) {
//按需获取,自动初始化
$vars = get_object_vars($api);
foreach ($vars as $key => $var) {
if (isset($api->$key)) {
$this->$key = $api->$key;
}
}
}
}然后,在接口Api中对Domain层的调用就会简化成:
$query = new Query_Demo($this); //自动初始化
$domain = new Domain_Demo();
$list = $domain->getList($query); //通过查询对象传递众多参数这样的好处在于:
- 1、更方便职能的划分
- 2、易于测试
- 3、实现简单(可提取一个Query的层超类来完成自动填充)
- 4、便于IDE时的参数提示,同时可以提供默认值





