第6章 重写历史遗留项目
在第5章,我们经历了WeTime创业项目从0到1的开发过程,所涉及的是PhalApi基础内容和高级主题的实际应用,并关注于如何在TDD下进行具体的接口服务开发。简而言之,WeTime项目侧重于小型项目的基本开发。而在这一章,我们面临的将是一个中型的项目,遇到的问题会更多,牵涉的技术会更广。除了对历史遗留项目进行重写,我们还会学习如何改善开发流程,改进软件构建过程,同时完善在WeTime项目中未能妥善解决的问题。可以说,这一章,更侧重于工具、扩展类库等在项目开发的综合应用,而不再是具体的代码编写。
6.1 项目背景
Family是一个家庭智能产品,最初的业务功能是通过摆放在家里的电子相框设备,可让家庭成员实时分享和浏览相片,增进家人的交流。但原来的后端系统是基于UCenter Home进行二次开发的,随着业务的迅速发展,原来的旧系统难以支撑功能的快速迭代和上线,并且由于之前不合理的设计,已日趋臃肿、缓慢、不稳定、维护成本高昂。特别是对于新增的母婴营养秤业务线,专门为孕妈和婴儿设计的全新产品,可用于记录、分析体重,设置体重增长计划,定制营养计划,为宝宝提供发育评估和喂养指导,基于历史原因,旧系统更是难于支撑。为此,经过慎重考虑,我们决定重写此历史遗留系统,并在重写完成的基础上支持新增的业务线。
注意,这里是重写,而不是重构。重构是不改变功能的前提下,改善既有的代码,而重写是把原有的系统重新开发一次。这是根据项目的实际情况而最终决定的,而不是鼓励大家轻易就重写旧系统,除非你有充分的理由。但这里的“重写”又非严格意义上的重写,因为我们开发了一个与原来功能一样的新系统,部署的是新的接口服务域名,使用的是新的数据库,配套的是新的App客户端。最后在完成重写的基础上,我们还增加了母婴营养秤业务线的功能模块。除此之外,我们不仅要重写系统以改善代码质量,还要规范开发流程以提高效率。
重写后的新系统,其项目名称为 Family 2.0,并且新版的App初次启动界面设计图如下:
图6-1 Family 2.0 新版App初次启动界面
通过这组启动界面,可以看出Family 2.0 相框功能的主要流程:家庭成员在家庭圈内分享照片后,便可在智能相框中浏览查看了。
这是一个更正式、更普遍、更具有代表性的开发项目。事不宜迟,让我们开始吧!
温馨提示:本次项目的源代码位于meet仓库的./src/Family-2.0目录下,并取自于真实项目。但为了保护实际项目的商业信息和出于教学的目的,代码未完全暴露并会有所调整。
6.2 重写历史遗留项目的前期准备
在开始重写旧版系统之前,需要进行一些前期准备工作。
6.2.1 数据库迁移
数据库迁移是一项基本的工作,需要将原来的数据库,进行重新设计,并将相关的业务数据导进新的数据库。选择重新设计,是因为原来的数据库存在设计不合理之处,并且随意时间的推移,大部分的表或字段已被废弃。但在Family 2.0 项目中,情况又有点特殊,数据库进行了重新设计,并且只导入了部分数据,这意味着,将不复用旧的业务数据。这是由业务层面决定的,因为产品人员希望通过Family 2.0 打造另一个家庭系统。为此,也大大减轻了数据库迁移这一重担。
具体的迁移过程,以及新的数据库表设计,这里暂不详细讲述,因为我们的关注点不在于此。
6.2.2 剖析已有的接口系统
在解决完数据问题后,接下来应该考虑项目代码了。对原来系统有多了解,重写后的系统还原度就越高。剖析已有的接口系统,是不可或缺的准备之一。
彻底理解原来的业务
先来了解一下,Family旧系统原来的核心业务功能。它一个典型的使用场景是,小明在外面使用Family在家庭圈发布一条含有相片的动态后,在家里的小明爸爸和小明妈妈等家庭成员便能通过摆放的电子相框实时相看刚更新的相片。
经过与产品经理一起梳理后,可得到原来的业务主要有以下功能模块:
- 用户模块 作为基本的功能模块,需要支持用户注册、登录,以及微信、新浪微博和QQ等第三方登录功能,支持用户信息的获取,修改与维护。
- 家庭圈模块 有了基本的用户,才能开始组建家庭圈。家庭圈是用于维护家庭成员的虚拟社交圈子,其功能按照维度划分可分为针对用户维度和针对家庭圈这两大类的功能。用户维度的功能有加入家庭圈、删除家庭成员;家庭圈维度的功能有生成家庭号、创建家庭圈、删除家庭圈和修改家庭圈名字等功能。一个用户可以创建多个家庭圈,一个家庭圈可以有多个成员。
- 动态模块 动态是指包括文本信息、相片素材甚至语音的内容,也是Family最核心的业务数据。其功能众多,为方便理解,这里可细分为三类,一类是针对动态的命令式操作,即会产生新数据或副作用的功能,如发布动态、转发动态、删除动态、收藏/取消动态;一类是针对动态的查询类操作,如获取家庭圈动态列表、获取设备动态列表、获取我的收藏列表、按关键字搜索动态;最后还有一类是关于动态评论的功能,如评论动态、获取动态评论列表、回复评论、删除评论。
- 相框模块 对于硬件设备电子相框而言,则需要提供相框登录,获取相框的登录信息,并为其分配UDID等功能。
可以看出,用户模块是基础,在这基础上才能实现家庭圈模板的开发。接着,是关键核心的动态模块,需要用户在登录的情况下,将动态发布在特定的家庭圈内。最后,通过电子相框进行展示。
旧系统的痛点与难点
好的系统都是类似的,不好的系统,各有各有痛点和难点。经过深入研究,发现原有的Family旧系统存在以下问题:
- 开发人员直接在生产环境进行即时修改,往往导致线上系统不稳定,因为开发人员随时都有可能在开发和调试。虽然有Git进行代码版本管理,Git只是作为一个备份的工具。
- 在同步的接口服务请求过程中,进行了大量耗时的操作,如邮件发送。但更让人惊讶的是,在发布动态的接口中,竟然会对用户当前家庭圈的全部成员进行同步的通知推送。试想一下,如果用户的家庭圈成员有100位的话,得需要多少时间!
- 分层结构不明显,或者说结构混乱,难以找到代码明确的执行顺序。对于新加入的开发人员,学习成本高。
- 代码文件过长,复杂度高,到处充斥着意大利式面条般的代码,藕断丝连,牵一发而动全身。只有长期维度它的开发人员才能勉强懂得如何进行修改,难以支撑业务的快速迭代。
- 系统响应时间高,但受限于数据库视图设计,难以进行性能优化,无法提供更顺畅的用户体验。
- 未经过优化的数据库查询,最为明显的是到处不考虑数据库“死活”的重复查询。在一次接口请求中,重复数据库的查询就有可能高达200多次,而这些重复的查询完全可以使用IN关键字优化成只有一次查询。以下是一个典型的示例:
SELECT * FROM user WHERE id = 1; SELECT * FROM user WHERE id = 2; SELECT * FROM user WHERE id = 3; ... ... SELECT * FROM user WHERE id = 200; - 没有任何单元测试,更多是凭借开发人员的主观意愿来判断功能的正确性,无法保证和可量化项目质量。
- 缺少有效的在线调试机制,不方便快速排查和定位线上问题,处理故障,SLA不高。
以上问题,涵盖了代码、数据库、开发流程、项目质量等方面。有问题不可怕,可怕是有这么问题,但我们却未发现,甚至根本不知道。我觉得,任何作为专业的软件开发工程师,都不能对这些问题熟视无睹。这些问题都是很有趣的,因为它不仅促进了我们构想对应的解决方案,还能引申出更多有挑战的问题,从而促进更多有效的思考。
下面来看一下,我们是如何解决这些痛点和难点的,又是如何进行有效思考的。
6.3 新接口系统的设计
既然使用PhalApi重写接口系统,那么我们需要在同时熟悉原有系统业务、痛点和难点,以及PhalApi框架的特性、工具和扩展类库,才能恰如其分地利用框架解决原来的问题。假设我们都已经熟悉PhalApi的基础内容和高级主题,如果不是,建议你回顾一下本书的第2章和第3章。因为下面更多是介绍如何应用,而不是重复介绍前面的知识内容。
6.3.1 客户端接入规范
此部分规范主要是针对客户端开发人员,以便与客户端约定接口服务的接入规范,同时对于需要提供怎样的接口服务也有极大的引导作用。
统一请求格式
- 1、接口服务HOST
测试环境HOST为:http://test.v2.api.family.com/
生产环境HOST为:http://v2.api.family.com/
- 2、公共参数
每个接口请求都需要传递的公共参数,目前已有的公共参数如下:
表6-1 Family 2.0 的公共参数
| 参数 | 是否必须 | 默认值 | 说明 |
|---|---|---|---|
| app_key | 是 | 客户端接入的key值,由后端分配提供,以及相应的密钥app_secrect | |
| sign | 是 | 加密后的签名,加密算法请见下面详细说明 | |
| service | 是 | 待请求的接口服务名称,由后端提供,其格式为“Class.Action” | |
| client | 否 | 客户端类型,值为:ios/android,区分大小写 | |
| device_agent | 否 | 终端设备名称, 如:iPhone 5s/MT27i/HuaWei X | |
| version | 否 | 客户端App当前版本号,格式建议使用X.X.X,如:1.0.1 | |
| UUID | 否 | 用户UUID,只有当接口需要获取用户相关信息才需要提供 | |
| token | 否 | 登录凭证,只有当接口需要进行身份验证时才需要提供 | |
| lan | 否 | 语言,值为:en/zh_cn,默认为zh_cn | |
| device_type | 否 | all | 设备类型;可选值:scale母婴称,cube为电子相框,all为全部设备类型 |
其中,生成sign的加密算法,步骤如下:
a、将全部请求的参数去掉sign后按参数名字进行字典排序
b、将字典排序后的全部参数名字对应的值依次用字符串连接起来
c、在b步的结果后面加上相应的密钥app_secrect后进行N次MD5(N次由项目指定)
以下是一个示例。假设,现有app_key为test,相应的密钥app_secrect为phalapi,那么对于待请求的链接:
http://v2.api.family.com/demo/?service=Default.Index&username=dogstar&app_key=test按参数名字进行字典排序后,可得:
app_key=test
service=Default.Index
username=dogstar依次把值用字符串连接起来,可得:
testDefault.Indexdogstar在后面加上相应的密钥app_secrect,为:
testDefault.Indexdogstarphalapi最后,进行N次MD5后,便可得到sign签名。最终在请求接口服务时,应该在添加参数,如:&sign=6fb2a3b48c258f561670e9b0044d6add。
- 3、通过POST传递非公共接口参数
对于公共参数,使用GET方式传递,而对于非公共参数,即特定接口服务的参数,建议统一使用使用POST传递,以免请求中因为数据处理不当而引起GET方式请求失败,同时长度不会受限,相对增强数据的安全性。
统一返回格式
- 1、JSOn格式与字段结构
统一以JSON格式返回:
{
"ret": 状态码,
"data": {
"code": 操作码,
"msg": "操作提示",
... ... // 更多业务数据
},
"msg": "错误提示"
}- 2、ret状态码
状态码主要分为三大系列,分别是:2XX正常请求,4XX客户端非法请求,5XX服务器错误。如表6-2所示。
表6-2 ret状态码说明
| 状态码(ret) | 说明 |
|---|---|
| 200 | 接口正常请求 |
| 4XX | 非法请求,如请求的服务不存在,签名失败,或缺少必要参数,由客户端调用不正确而引起 |
| 401 | 缺少登录态或者登录态已失效,此时需要重新登录 |
| 406 | 签名失败,验签不成功,或者app_key/app_secrect有误 |
| 5XX | 服务器运行错误,此部分需要后端开发人员修复 |
- 3、业务数据
业务数据部分包含了客户端需要获取的业务数据,通常会有code和msg字段,其中: code细分为业务操作的结果,并且code为0时表示成功;msg则为对应的显示文案。业务数据data的具体返回格式,请见各个接口的详细说明。
- 4、错误提示
此部分的错误提示主要是针对开发人员提供的,不应该显示给用户,以免给用户带来困惑或者显露一些接口内部的细节。
客户端开发人员可以根据此块的错误提示,获取一些指导信息。只有当ret不为200时,此错误提示信息才不为空。
- 5、一个返回示例
如在微信成功登录的情况下,会返回:
{
"ret": 200,
"data": {
"code": 0,
"info": {
"UUID": "AAAKLJFKLJUE889UFLKAKDF1k23j14lk",
"token": "430C0F31FAF1FB1565E4290D1B61185A2408A6DEEA1604C1B5AEB14E44BDF2E0",
"is_new": 0
},
"msg": ""
},
"msg": ""
}6.3.2 服务端开发规范
除了制定了客户端接入规范,我们在Family 2.0 项目中还制定了服务端开发规范。希望此开发规范,能约束开发人员产出更优质的代码,并作为快速开发教程,为新加入的团队成员提供指引和帮助,降低学习成本。
- 1、Git代码签出
新项目成员需要与项目经理申请Git帐号和权限,并创建各自对应的个人开发分支或者协同开发分支,然后在本地开发环境进行代码签出和部署。
-
2、开发流程
- a、测试先行
根据PhalApi框架所推荐的TDD一般开发步骤,在编写产品代码前,先编写测试代码。可使用phalapi-buildtest命令来生成单元骨架代码。 - b、实现接口服务
在测试驱动开发的指导下,根据从Api接口层、Domain领域层再到Model数据源层的顺序进行开发。 - c、提供文档
除了提供PhalApi在线接口文档外,还需要参考附录A,编写提供接口服务文档。 - d、与客户端联调
当接口服务开发完成并自测通过后,与客户端开发人员进行必要的开发联调。 - e、数据库变更
当有数据库变更时,如服务器迁移、新加表或字段等,请将变更的SQL语句保存到./Config/sql目录下,并同步外网环境。
- a、测试先行
- 3、常用操作
对于登录态验证,可以有两种检查方式,一种是在失败时直接抛出异常的拦截式检测,另一种是在失败时返回检测结果的温柔式检测。分别如下:
// 拦截式检测:如果未登录时,直接400返回
DI()->userLite->check(true);
// 温柔式检测:获取登录的情况,为不同的业务提供不同的选择
DI()->userLite->check();对于原始的数值型的用户ID,由于其可遍历性,为了保障用户信息的安全性,需要将数字转换成不可遍历、更复杂的字符串。对于这两者之间的互相转换,可以使用:
// UUID --> userId
$userId = Domain_User_Helper::UUID2UserId('AAAD56B5460339234A4A2492680171A88818B96B8D8DA687FB');
// userId --> UUID
$UUID = Domain_User_Helper::userId2UUID(187);- 4、约定编程
接口参数、返回字段、数据库的字段,这些外部可见的数据全部使用下划线分割的格式,如:
接口参数:
// 正确的
&user_id=888
// 错误的
&userId=888返回字段:
// 正确的
"device_type": "cube",
// 错误的
"deviceType": "cube",数据库字段:
-- 正确的
`user_id` bigint(20) DEFAULT '0' COMMENT '创建者的用户ID',
-- 错误的
`userId` bigint(20) DEFAULT '0' COMMENT '创建者的用户ID',内部PHP代码变量则使用驼峰命名法,如:
接口参数规则:
// 正确的
'otherUserId' => array('name' => 'other_user_id', 'type' => 'int', 'min' => 1, 'require' => true),
// 错误的
'other_user_id' => array('name' => 'other_user_id', 'type' => 'int', 'min' => 1, 'require' => true),- 5、一键测试
在测试环境上,执行以下命令可进行一键测试:
$ ./run_tests运行效果类似:

图6-2 一键测试的运行效果
一键测试,作为持续集成的一部分,应该随时、频繁执行,以校验接口服务的正确性,最大限度保证项目质量。如果做不到持续集成,至少在以下场景中应当执行一键测试: 发布版本到生产环境前;更新PhalApi框架后;进行大范围改动,或底层修改后。
6.3.3 多入口,多模块
Family 2.0 业务模块主要有原有的业务线智能电子相框,以及新增的业务线母婴营养称。需要服务的客户端除了安卓、iOS移动设备外,还有PC版的客户端和PC端的管理后台系统,除此之外,还有电子相框和营养称这些硬件设备。为清晰划分这些不同的模块,经过不断迭代,最终创建的项目有:
- Fami项目 提供重写原有接口系统后的接口服务,包括原有的用户模块、家庭圈模块、动态模块和电子相框模块。并且作为整个系统的基础项目,提供公共接口服务。
- Scale项目 提供新增的母婴营养称业务线的接口服务,包括了秤模块、体重模块、食谱模块等。可结合营养秤上报的体重进行分析,然后提供改善建议。
- Admin项目 主要针对管理后台系统提供接口服务,用于实现下订购买、售后服务、后台运营等功能。
- Task项目 负责用于计划任务的耗时接口服务的实现,如为商家生成一系列设备信息,进行消息推送等。
- PC项目 针对PC版客户端提供AJAX接口,由于此场景不适宜采用签名加密,所以需要自定义接口服务白名单,以便前端能正常调用指定的接口服务。
上面所说的项目,是指放置源代码的项目,类似默认的Demo项目,每个项目都是可作为单独的子系统。这些项目都位于根目录的Apps目录下。
Family-2.0$ tree ./Apps/
./Apps/
├── Admin
├── Fami
├── Pc
├── Scale
└── Task经过综合考虑,决定对外提供多个访问入口,这些入口与上面划分的项目对应,但又有所变化,主要有:
- 电子相框访问入口/fami 对外提供Fami项目的接口服务。
- 母婴营养秤访问入口/scale 对外提供Scale项目的接口服务,但内部实现依赖于Fami项目。
- 管理后台访问入口/admin_28***4 为管理后台提供Admin项目的接口服务,但内部实现依赖于Fami项目和Scale项目。增加数字后续是为了避免外界简单地猜测到此入口路径。
- PC端访问入口/web 对外提供Fami项目和Scale项目的部分接口服务,并且不需要任何签名验证。
由于Task计划任务的接口服务都是本地调用,故不需要对外提供访问入口。
6.3.4 通过系统变量维护服务器配置
原有的系统,使用硬编码的方式配置数据库连接等配置信息。一如常见的:
'servers' => array(
'db_demo' => array( //服务器标记
'host' => 'localhost', //数据库域名
'name' => 'phalapi', //数据库名字
'user' => 'root', //数据库用户名
'password' => '', //数据库密码
'port' => '3306', //数据库端口
'charset' => 'UTF8', //数据库字符集
),
),为了更方便在不同环境下,在不改动任何代码的情况下实现快速部署,在Family 2.0 系统中全部数据库链接、Memcache链接等配置信息采用系统环境变量的方式配置。例如,上面的配置换为:
'servers' => array(
'db_A' => array( //服务器标记
'host' => $_ENV['FAMILY_V2_DB_HOST'], //数据库域名
'name' => $_ENV['FAMILY_V2_DB_NAME'], //数据库名字
'user' => $_ENV['FAMILY_V2_DB_USER'], //数据库用户名
'password' => $_ENV['FAMILY_V2_DB_PASS'], //数据库密码
'port' => $_ENV['FAMILY_V2_DB_PORT'], //数据库端口
'charset' => $_ENV['FAMILY_V2_DB_CHARSET'], //数据库字符集
),
),下面分别简单介绍,对于本书的开发环境,对于cli命令行和php-fpm这两种模式如何配置这些系统变量。
php-fpm下如何配置系统变量
首先,确保在php.ini配置文件中已经开启$_ENV全局变量。可打开/etc/php5/fpm/php.ini配置文件,并确保variables_order值为“EGPCS”,其中首字母E表示$_ENV全局变量。即:
# vim /etc/php5/fpm/php.ini
variables_order = "EGPCS"其次,在php-fpm相应的配置文件中添加相应的env配置,如:
# vim /etc/php5/fpm/pool.d/www.conf
env[FAMILY_V2_DB_HOST]=$FAMILY_V2_DB_HOST
env[FAMILY_V2_DB_NAME]=$FAMILY_V2_DB_NAME
env[FAMILY_V2_DB_USER]=$FAMILY_V2_DB_USER
env[FAMILY_V2_DB_PASS]=$FAMILY_V2_DB_PASS
env[FAMILY_V2_DB_PORT]=$FAMILY_V2_DB_PORT
env[FAMILY_V2_DB_CHARSET]=$FAMILY_V2_DB_CHARSET接着,在/etc/profile中,添加相应的系统变量。即:
# vim /etc/profile
export FAMILY_V2_DB_HOST=localhost
export FAMILY_V2_DB_NAME=phalapi
export FAMILY_V2_DB_USER=root
export FAMILY_V2_DB_PASS=''
export FAMILY_V2_DB_PORT=3306
export FAMILY_V2_DB_CHARSET=UTF8为了让php-fpm每次重启时能自动加载系统变量,可以修改php-fpm的启动脚本,并在合适的位置添加source操作,即:
# vim /etc/init.d/php5-fpm
. /etc/profile配置好后,重启php-fpm。
# service php5-fpm restart重启后便可以通过代码的$_ENV读取到相应的系统环境变量了,在保护敏感配置信息的同时,还可以实现不同环境下的配置切换和管理。此外,这里还有一个小技巧,对于域名可以再配置HOST,指向特定的IP地址。
cli下如何配置系统变量
相比之下,cli下的配置要比php-fpm下的要简单得多。只需要在/etc/environment文件中配置系统变量后,但可以通过代码的$_ENV进行读取了。例如:
# vim /etc/environment
export FAMILY_V2_DB_HOST=localhost
export FAMILY_V2_DB_NAME=phalapi
export FAMILY_V2_DB_USER=root
export FAMILY_V2_DB_PASS=''
export FAMILY_V2_DB_PORT=3306
export FAMILY_V2_DB_CHARSET=UTF8编辑保存后,只需要source一下,便可生效。
6.3.5 在线接口文档
在Family 2.0 项目中,除了按照接口模样提供文档外,我们还充分利用了PhalApi框架提供的在线接口文档。客户端在实时生成的在线文档获取最新最可靠的信息,也可以通过手动编写的文档获取更多补充的说明。这两份文档是相互相成的。为了充分使用在线接口列表文档和在线接口详情文档,就需要按PhalApi的规范编写注释和配置参数规则。
最终手动编写的接口文档约有130多份,以下是其中的部分文档列表。

图6-3 部分手动编写的接口文档
6.3.6 扩展类库的应用
在开发业务系统时,经常会看到重复通用的功能模块。结合Family 2.0 的项目情况和业务场景,为了减少重复开发的成本,提升开发效率,我们使用了User、Task和Qiniu等扩展类库,快速地搭建好了基础设施层,为实际具体的业务功能开发提供了更丰富的支持。
User用户扩展
对于用户模块,我们基于User用户扩展进行了二次开发,以满足特定业务场景的需要。集成后,最终的使用和User扩展类库的使用基本一致。例如,前面已经讲述判断用户是否已登录的方式。
// 拦截式检测:如果未登录时,直接400返回
DI()->userLite->check(true);
// 温柔式检测:获取登录的情况,为不同的业务提供不同的选择
DI()->userLite->check();Task计划任务扩展
Family 2.0 项目中有很多耗时的操作,这些操作应该通过后台异步计划任务进行调度。例如为商家生成一系列设备信息,进行消息推送等。为此,我们集成了Task计划任务扩展,这样开发人员只需要开发实现具体的业务功能即可,其他的工作则交由Task扩展来完成。不仅流程质量得到了保障,同时也分离了关注点,降低开发难度。
Qiniu七牛扩展
在小的项目中,图片等文件往往是上传到本地服务器。但对于一定规模的系统来说,这种简单粗暴的方式是行不通的。因为存放在本地服务器的文件,不能在服务器集群内进行共享;其次,这些上传的文件不仅占据了服务器有限的硬盘空间,还会在访问时消耗大量的网络带宽,从而间接影响了接口服务的吐吞量;最后也不方便对上传的文件进行管理,如添加CDN加速访问。在现在这个时代,是技术领域细分的时代。专业的事,应该交由专业的团队去处理。一如,对于上传的图片文件,可以考虑交给第三方CDN服务。Family 2.0 项目也需要上传图片文件,故此我们选择了七牛云存储,并相应地集成了Qiniu七牛扩展。
6.4 重写既有的接口服务
需要重写的接口服务有很多,这里不能一一列出。但我会把在这个重写过程中,如何有效使用PhalApi所提供的特性、设计模式、扩展类库和方法技巧这些经验与大家分享。
6.4.1 数据库分表
Family 2.0 项目的数据库名为:familyv2,并约定统一的表前缀为“fami”。考虑到Family 2.0 项目数据量大,为方便后期的数据库服务器水平扩容,我们对数据量大且不需要进行关联查询的表进行了分表配置。例如,对于动态的评论内容,其评论表fami_feed_comments数据量大,只需要与动态关联,而评论与评论间不需要进行关联查询,因此适合采用分表策略。此时,首先配置的是数据表路由规则。
// $ vim ./Config/dbs.php
'tables' => array(
... ...
// 评论表 - 100张分表
'feed_comments' => array(
'prefix' => 'fami_',
'key' => 'id',
'map' => array(
array('db' => 'db_A'),
array('start' => 0, 'end' => 99, 'db' => 'db_A'),
),
),
),虽然目前100张分表都使用了db_A这一数据库实例,但通过这种配置,可以在需要的时候进行相应的调整。
接下来,准备存放评论表的基本字段的sql文件。注意不需要添加主键id和扩展数据ext_data这两个字段。即:
-- $ vim ./Data/feed_comments.sql
`feed_id` bigint(20) DEFAULT '0',
`user_id` bigint(20) DEFAULT '0' COMMENT '发布评论的用户ID',
`message` text COMMENT '评论内容',
`to_comment_id` bigint(20) DEFAULT '0' COMMENT '针对评论的回复,为0时表示对动态>评论',
`to_user_id` bigint(20) DEFAULT '0' COMMENT '被评论者的用户id',
`dateline` int(11) DEFAULT '0' COMMENT '评论的时间戳',随后,可以使用phalapi-buildsql脚本命令为此评论表生成创建这100个分表的SQL语句,执行此命令,传递相应的参数,以及生成输出的SQL语句为:
$ Family-2.0$ ./PhalApi/phalapi-buildsqls ./Config/dbs.php feed_comments
CREATE TABLE `fami_feed_comments_0` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`feed_id` bigint(20) DEFAULT '0',
`user_id` bigint(20) DEFAULT '0' COMMENT '发布评论的用户ID',
`message` text COMMENT '评论内容',
`to_comment_id` bigint(20) DEFAULT '0' COMMENT '针对评论的回复,为0时表示对动态评论',
`to_user_id` bigint(20) DEFAULT '0' COMMENT '被评论者的用户id',
`dateline` int(11) DEFAULT '0' COMMENT '评论的时间戳',
`ext_data` text COMMENT 'json data here',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `fami_feed_comments_1` ... ...
CREATE TABLE `fami_feed_comments_2` ... ...
CREATE TABLE `fami_feed_comments_3` ... ...
.. ...
CREATE TABLE `fami_feed_comments_99` ... ...检验没问题后,可重定向保存到临时文件,如/tmp/fami_feed_comments.sql,再导入到数据库。
完成配置和创建好数据库分表后,接下就是评论数据模型Model类的实现。
// Family-2.0$ vim ./Apps/Fami/Model/FeedComments.php
<?php
class Model_FeedComments extends PhalApi_Model_NotORM {
const TABLE_NUM = 100;
protected function getTableName($id = null) {
$tableName = 'feed_comments';
if ($id !== null) {
$tableName .= '_' . ($id % self::TABLE_NUM);
}
return $tableName;
}
}其他需要使用分表的情况也可以类似这样配置和实现。在项目初期,就确定好哪些数据库表需要分表是大有裨益的。程序是数据结构加算法,可想而知,数据在系统项目中所处的重要位置。有什么样的数据结构,就决定了怎样的算法。同样,有什么的存储方式,就影响了如何编写程序的代码。
下面是评论领域业务类的相关代码片段,这些代码展示了在分表的情况下,如何编写代码。
// Family-2.0$ vim ./Apps/Fami/Domain/Feed/Comment.php
/**
* 分表存储 + 刷新评论数量
*/
protected function commonComment($newData) {
$model = new Model_FeedComments();
$id = $model->insert($newData, $newData['feed_id']);
//刷新评论数量
$domain = new Domain_Feed();
$domain->refreshCommentNum($newData['feed_id']);
return intval($id);
}细心的读者可以发现,在调用insert方法进行添加数据时,会添加第二个参数$newData['feed_id']。此参数表示是动态ID字段,用于进行分表的依据。并且注意到在为动态添加评论内容后,需要刷新动态的评论总数量,以便缓存耗时但每次查询结果都一样的值。
6.4.2 用特征草图分解“万能类”
在有一定历史的旧系统中,最为常见的是什么都做的“万能类”。这些类,往往没有明确的职责,而是当有新的功能代码时不加思考,为图方便就直接加在里面,久而久之,就慢慢变成了一个“万能类”。在它里面的方法,大部分都是静态方法,并且在一定程序上有所关联,看起来更像是糅合了多个协作类的全部接口功能。
对于“万能类”,在重写或者平时重构过程中,应该将其进行分解,使之更符合单一职责原则。那么问题是,面对臃肿,成千上万行的代码,我们应该怎么有序地进行分解?在我曾经入职的一家公司,我的上级跟我说过:最终结果和方式、过程,同样重要。下面来看下,使用什么方式,如何分解“万能类”。
先来介绍一个有用的工具,它虽然简单,但非常实用。它的名字叫特征草图,出自某本技术书籍。它的使用过程是这样的:打开需要分解的类,准备笔和草稿纸,以成员属性为矩形,成员函数为椭圆,并用实线的单向箭头表示依赖使用关系,最后便可得到此类的特征草图。下面是一个简单示例类:
<?php
class Person {
protected $name;
protected $money = 0;
public function __construct($name) {
$this->name = $name;
}
public function getName() {
return $this->name;
}
public function earn($money) {
$this->money += $money;
}
public function getMoney($money) {
return $this->money;
}
}Person是一个表示人员的类,它有两个成员属性,分别是表示名字的$name和表示所持有的金钱$money。对于名字,有简单的getter方法,而对于金钱,除了简单的getter方法外,还有赚钱的成员函数。根据绘画特征草图的方法,可以得到图6-4。
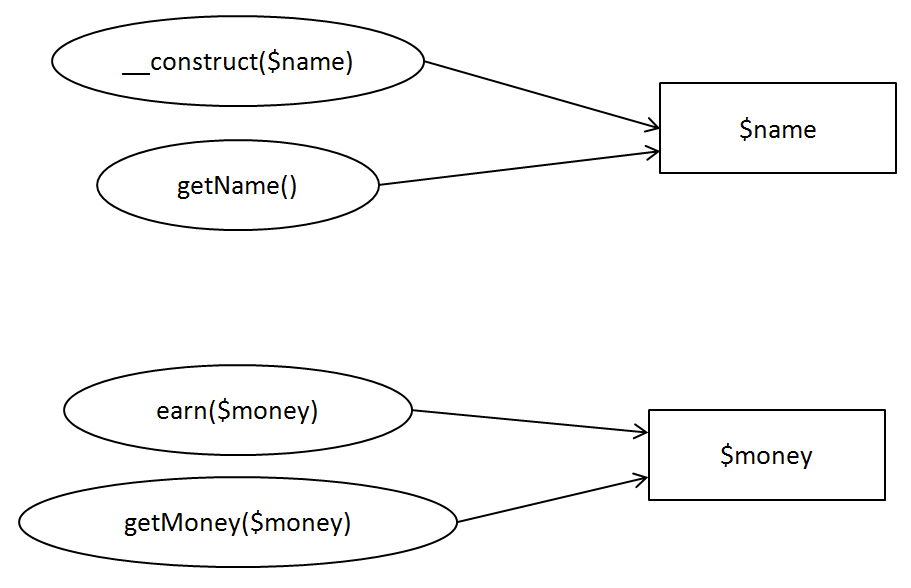
图6-4 Person类的特征草图
通过手动绘画类的特征草图,不仅操作简单,而且可以清晰地发现成员函数和成员属性在逻辑上的依赖关系。例如在上面的Person类中,可以分解为两个类,一个类只负责人员基本信息,而另一个类则只负责赚钱。
当然,实际中根据历史遗留系统中的“万能类”画出来的特征草图并没有那么简单,但也能从中发现一些端倪。一个经验法则是,通常在特征草图中会存在一个汇点,以此汇点为切入点画一条直线,便可把原来庞大的类一分为二。你发现的汇点越多,最终分解的类就越清晰。那么汇点是什么呢?它往往是某个成员函数,并且是承上启下的一个关键节点,类似两个逻辑世界的通道。如图6-5,灰色的椭圆节点即为汇点,虚线表示可以把上、下两组成员函数和成员属性分解到两个类中。

图6-5 带有汇点的特征草图
那汇点本身这一成员函数应该划分在哪个拆分类里呢?汇点箭头以下的部分,使用抽取子类的重构方法,可以得到一个分解后的类。通常汇点应通过提取子函数的重构方法迁移到分解后的新类中,而在原来的成员函数里,使用委托,调用新的类方法。
如此,通过使用特征草图作为参考依据,结合恰当的重构方法,便可对臃肿的类进行很好的分解,最终得到职责更单一,更内聚的类。
6.4.3 消化复杂的领域业务
Family 2.0 一个很重要的业务是加入家庭圈。图6-6的交互设计图展示了从创建家庭圈到加入家庭圈这一过程。具体的场景可描述为:用启根据四位数字的家庭号和密码,可加入指定已创建的家庭圈。这一过程因为有着各种规则,蕴含着领域业务,因此在开发实现上是有一定复杂度的。下面,一起来看下如何消化复杂的领域业务。
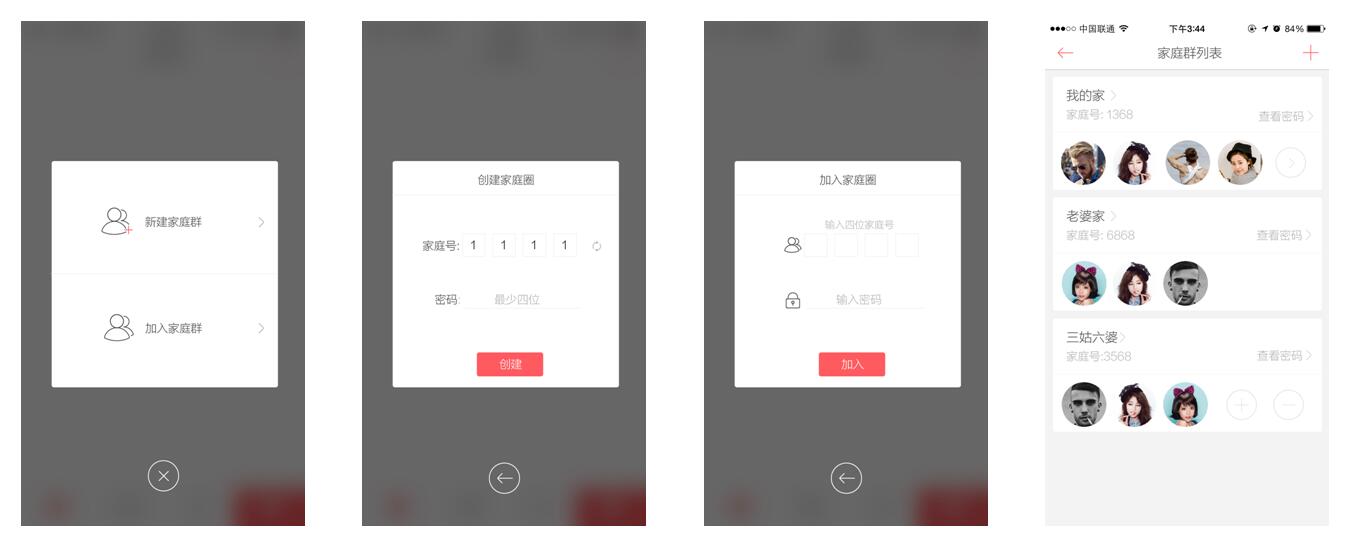
图6-6 加入家庭圈的操作流程
为了更加了解这其中细致的业务规则,让我们来看下当时为加入家庭圈这一接口服务所写的测试用例。
// Family-2.0$ vim ./Apps/Fami/Tests/Api/Group/Api_Group_Member_Test.php
public function testJoinGroup()
{
DI()->notorm->group_member->where('user_id', 110)->delete();
// Step 1. 构建请求URL
$url = 'app_key=mini&client=ios&version=1.0.0&service=Group_Member.JoinGroup&sign=8c3b4&__debug__=1&UUID=A3D779AF491F86ECFCD22F05CD6A9D1C9F8719CFE4BCEA06B0&group_num=1763&group_pwd=1111';
// Step 2. 执行请求
$rs = PhalApi_Helper_TestRunner::go($url);
// Step 3. 验证
$this->assertNotEmpty($rs);
$this->assertArrayHasKey('code', $rs);
$this->assertArrayHasKey('group_id', $rs);
$this->assertEquals(0, $rs['code']);
$this->assertGreaterThan(0, $rs['group_id']);
// 不能再次加入
$rs = PhalApi_Helper_TestRunner::go($url);
$this->assertEquals(3, $rs['code']);
// 家庭圈密码错误
$url = 'app_key=mini&client=ios&version=1.0.0&service=Group_Member.JoinGroup&sign=8c3b4&__debug__=1&UUID=A3D779AF491F86ECFCD22F05CD6A9D1C9F8719CFE4BCEA06B0&group_num=1763&group_pwd=1112';
$rs = PhalApi_Helper_TestRunner::go($url);
$this->assertEquals(2, $rs['code']);
// 家庭圈不存在
$url = 'app_key=mini&client=ios&version=1.0.0&service=Group_Member.JoinGroup&sign=8c3b4&__debug__=1&UUID=A3D779AF491F86ECFCD22F05CD6A9D1C9F8719CFE4BCEA06B0&group_num=4444&group_pwd=1111';
$rs = PhalApi_Helper_TestRunner::go($url);
$this->assertEquals(1, $rs['code']);
}上面的测试用例不是特别好的写法,因为它里面同时测试了几个场景。但通过这些测试场景,可以看到,我们验证了一个ID为110的用户,凭家庭圈密码1111加入了家庭号为1763的家庭圈这一Happy Path。此外,验证了不能重复加入同一个家庭圈、以及家庭圈密码错误、家庭圈不存在这些异常的场景。
有了明确业务规则的单元测试作指引,接下来遵循ADM分层模式,便可进行逐步分解,最后得到井然有序、易于理解、可测试的代码。以下是加入家庭圈Api接口层的实现代码片段。
// Family-2.0$ vim ./Apps/Fami/Api/Group/Member.php
class Api_Group_Member extends PhalApi_Api {
public function getRules() {
return array(
'joinGroup' => array(
'groupNum' => array('name' => 'group_num', 'require' => true, 'min' => 4),
'groupPwd' => array('name' => 'group_pwd', 'require' => true, 'min' => 4),
'deviceType' => array('name' => 'device_type', 'type' => 'enum', 'range' => array('all', 'cube', 'scale'), 'default' => 'all'),
),
);
}
public function joinGroup() {
$rs = array('code' => Common_Def::CODE_OK, 'group_id' => 0, 'msg' => '');
DI()->userLite->check(true);
//step 1. check
$domain = new Domain_Group();
$groupId = $domain->getGroupIdByGroupNum($this->groupNum);
$rs['group_id'] = $groupId;
if ($groupId <= 0) {
$rs['code'] = 1;
$rs['msg'] = T('group {number} not exists', array('number' => $this->groupNum));
return $rs;
}
//step 2. check pwd
if (!$domain->checkPassword($groupId, $this->groupPwd)) {
$rs['code'] = 2;
$rs['msg'] = T('group passwrod wrong');
return $rs;
}
//step 3. check has joined
$memberDomain = new Domain_Group_Member();
if ($memberDomain->hasJoined($this->userId, $groupId, $this->deviceType)) {
$rs['code'] = 3;
$rs['msg'] = T('has joined the group memeber');
return $rs;
}
//step 4. join
$memberDomain->joinGroup($this->userId, $groupId);
$rs['group_id'] = $groupId;
return $rs;
}
代码虽然有点长,但并不影响它的阅读性以及可理解性。在Api_Group_Member::getRules()成员函数中,配置了接口服务所需要的参数,分别是用户的UUID、四位数的家庭号和四位数的家庭密码、设备类型。接下来,是加入家庭圈的实现代码。在Api_Group_Member::joinGroup()中,最前面通过User扩展类库进行了登录态的检测。然后便是加入家庭圈的业务流程,第一步先检测待加入的家庭号是否合法;第二步校对家庭圈密码;第三步判断是否已加入;最好第四步进行加入操作。可以看到,很明显地,前面三步都是查询操作,而最后一步属于命令式操作,即会产生副作用。这也是符合命令查询职责分离模式原则的。而这些操作,也是在同一个高度的层次,对业务规则进行了很好的表达。至于具体内部的业务实现规则,可以再深入到对应的领域业务类,看下它又是如何表达和实现规则的。
例如,对于负责家庭圈成员的Domain_Group_Member领域业务类。一如我们所期望的,在判断用户是否已加入家庭圈的实现代码中,果然依赖了来自Model层的数据。
// Family-2.0$ vim ./Apps/Fami/Domain/Group/Member.php
class Domain_Group_Member {
public function hasJoined($userId, $groupId, $detectDeviceType = 'all', $deleteState = Domain_Group_Helper::GROUP_NOT_DELETE) {
$model = new Model_GroupMember();
return $model->hasJoined($userId, $groupId, $detectDeviceType, $deleteState);
}
}这对于项目开发来说,是一件很棒的事情!因为遵循ADM分层模式的代码具有可预测性,不管是哪位开发人员来实现,最后产出的代码都是和我们共同所期待的结构是一致的。这样,则可以大大降低了代码的维护成本。再来看下在Domain_Group_Member领域业务类中加入家庭圈的实现代码, 下面代码是否和你想象的相差无几?
// Family-2.0$ vim ./Apps/Fami/Domain/Group/Member.php
class Domain_Group_Member {
public function joinGroup($userId, $groupId) {
if ($userId <= 0 || $groupId <= 0) {
return false;
}
$newData = array();
$newData['user_id'] = $userId;
$newData['group_id'] = $groupId;
$model = new Model_GroupMember();
$id = $model->insert($newData);
return $id > 0 ? true : false;
}
}最后,稍微看一下对应Model层的实现代码片段。
// Family-2.0$ vim ./Apps/Fami/Model/GroupMember.php
class Model_GroupMember extends PhalApi_Model_NotORM {
protected function getTableName($id = null) {
return 'group_member';
}
public function hasJoined($userId, $groupId, $detectDeviceType = 'all', $deleteState = Domain_Group_Helper::GROUP_NOT_DELETE) {
$num = $this->getORM()
->where('user_id', $userId)
->where('group_id', $groupId)
->count('id');
return $num > 0 ? true : false;
}
}就这样,通过层层分解,我们再一次优雅地消化了复杂的领域业务,以一种可预测、职责划分明确的方式完成了代码的编写,功能的开发。当然,每个接口服务所布面临的领域业务不尽相同,这里只是作为一个示例,希望能给大家提供一些启发性。
6.5 开发新增的接口服务
完成了既有接口服务的重写任务后,下一步将要进行的是开发新增的接口服务。下面,介绍的是在开发新接口服务过程中所遇到的难题,以及解决的思路和方案。
6.5.1 有趣的体重数据
在Faimly 2.0 项目中,需要新增的功能业务线是母婴营养称。而在母婴营养称中,比较有趣的是用户通过家里的电子称上报的体重数据。这份体重数据是整个业务的数据基础,因此它的重要性很高。在开发与体重数据相关的接口服务时,不仅要考虑到功能性的要求,还要满足非功能性的要求。
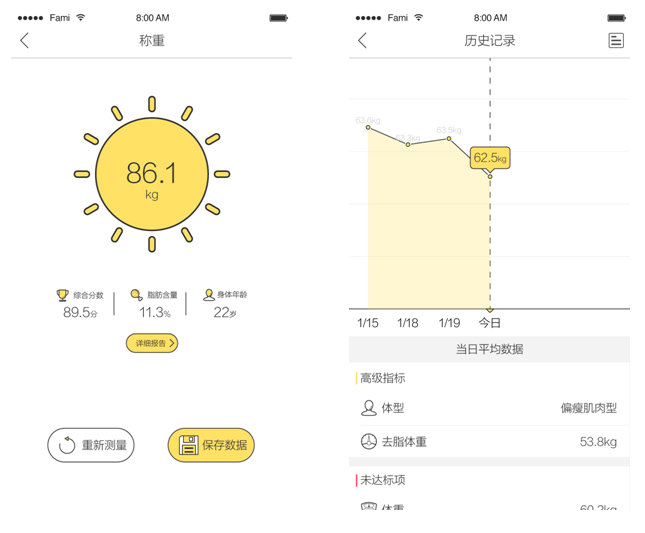
图6-7 体重上报与列表设计稿
如图6-7所示,用户可以通过家里的电子称获得体重数据后,经过蓝牙传递给移动App,最后点击“保存数据”即可上传体重数据。然后可以在移动App中查看自己的休重历史记录,并获得相应的营养建议。考虑到这份基础数据有着可预见性的增长,因为用户每时每刻都有可能在测量上传体重数据,所以我们对其进行了分表设计,并分为512张数据库表,为区分与原来系统间的数据库表,新业务所用的数据库表使用前缀“scale_”,表名为:sweight,即分表分别是:scale_sweight_0、scale_sweight_1、scale_sweight_2、scale_sweight_3、……、scale_sweight_511。体重表的基础表字段如下:
-- Family-2.0$ vim ./Data/sweight.sql
`user_id` bigint(20) DEFAULT NULL,
`weight` int(7) DEFAULT '0' COMMENT '体重(单位用g)',
`report_date` int(11) DEFAULT '0' COMMENT '体重上报时间戳',
`type` tinyint(2) DEFAULT '0' COMMENT '体重阶段:0普通人/产前,1孕妇,2抱婴(产后)',
`baby_position` tinyint(4) DEFAULT '0' COMMENT '宝宝的位置,1老大,2老二,3老三(为0时表示不是宝宝的体重)',
`report_short_date` varchar(8) DEFAULT '' COMMENT '短的日期,格式如:20150501',
`cur_day_position` smallint(3) DEFAULT '1' COMMENT '当天上报第几次上报',再来稍微看一下在上传体重数据时,是怎样的一个过程。下面是上传体重接口服务对应的Api接口层的代码片段。
// Family-2.0$ vim ./Apps/Scale/Api/Device/Scale.php
class Api_Device_Scale extends PhalApi_Api {
public function getRules() {
return array(
'uploadWeight' => array(
'weight' => array('name' => 'weight', 'type' => 'int', 'min' => 0, 'max' => 250000, 'default' => 0, 'require' => true),
'type' => array('name' => 'type', 'type' => 'enum', 'range' => array(0, 1, 2), 'default' => 0, 'require' => true),
'babyPosition' => array('name' => 'baby_position', 'type' => 'int', 'default' => 0, 'require' => false),
'babyWeight' => array('name' => 'baby_weight', 'type' => 'int', 'min' => 0, 'max' => 250000, 'default' => 0, 'require' => false),
),
);
}
}上面配置的参数规则中,weight表示待上服的体重数据。再来看下实现代码。
public function uploadWeight() {
$rs = array('code' => Common_Def::CODE_OK, 'msg' => '');
if ($this->type != 2 && $this->babyPosition != 0) {
throw new PhalApi_Exception_BadRequest(T('baby position is not 0'));
}
DI()->userLite->check(true);
$domain = new Domain_SWeight();
$domain->addWeight($this->userId, $this->weight, $this->type, $this->babyPosition, $this->babyWeight);
if ($this->type == 1) {
// 设置最新的体重(type为1时,表示孕妇的,妈妈的数据是存在 smother 表里;type为2时,妈妈的数据是存在 suser 表里)
$motherDomain = new Domain_SMotherInfo();
$motherDomain->initDefaultUserDataIfNoUserData($this->userId);
if ($this->weight > 0) {
$motherDomain->freeUpdate($this->userId, array('newest_weight' => $this->weight));
}
} else {
// 设置最新的体重(type为1时,表示孕妇的,妈妈的数据是存在 smother 表里;type为2时,妈妈的数据是存在 suser 表里)
$commonDomain = new Domain_SInfo();
$commonDomain->initDefaultUserDataIfNoUserData($this->userId);
if ($this->weight > 0) {
$commonDomain->freeUpdate($this->userId, array('newest_weight' => $this->weight));
}
}
if ($this->type == 2) {
// 设置宝宝最新的体重
$babyDomain = new Domain_SBabyInfo();
$babyDomain->initDefaultUserDataIfNoUserData($this->userId, $this->babyPosition);
if ($this->babyWeight > 0) {
$babyDomain->freeUpdate($this->userId, $this->babyPosition, array('newest_weight' => $this->babyWeight));
}
}
return $rs;
}通过区分不同的体重类型,然后将体重数据保存到相应的位置,并且会用户初次上传体重数据时,进行前置的初始化操作。至此,我们就完成了体重这一基础数据的服务构建。接下来,是基于这份数据而衍生出来更复杂的业务。
6.5.2 善于解决复杂问题的设计模式
在前面,我们介绍了如何通过ADM分层模式有效地消化复杂的领域业务。这对于一般性的复杂业务是可行的,但对于特定的复杂业务,则需要适当地采用设计模式,方能有效进行解决。那何谓特定的复杂业务呢?这里的定义比较笼统,可以理解成设计模式所解决的重复性问题,也可以理解成是业务系统中比较关键、变化较多、规则繁重的区域。以Family 2.0 系统中的推送为例,有两大类推送服务,一类是周期固定的主动推送,如每日推送、每周推送和每月推送;另一类是特定场景下的触发推送,如新注册用户推送。最终总结得出,需要的推送接口服务有以下这些:
- 周营养计划推送
- 月计划推送
- 孕妇欢迎语推送
- 产后妈妈首次推送
- 针对宝宝的月推送
- 周报推送
- 孕妇周营养计划推送
更具有挑战性的是,每种推送的实现逻辑都异常复杂,但又存在一定程度上的相似性。当时,最初我看到产品整理的推送需求,是非常惊讶的。因为里面的规则非常细致,在惊叹产品经理有如此缜密思维的同时,我也在思考如何清晰地把这些规则准确无误去表达出来。第一时间想到的就是,对于如此复杂的领域问题,应该采用设计模式来解决。经过综合评估,模板方法是最为贴切的选择。
为了验证最终实现的效果,以及提高我们的关注点。先来编写一个单元测试用例。
// Family-2.0$ vim ./Apps/Scale/Tests/Domain/Domain_SPush_Week_Test.php
class PhpUnderControl_DomainSPushWeek_Test extends PHPUnit_Framework_TestCase
{
public $domainSPushWeek;
protected function setUp()
{
parent::setUp();
$this->domainSPushWeek = new Domain_SPush_Week();
}
public function testPush() {
DI()->notorm->spush_record->where('user_id', 187)->where("type like '%week%'")->delete();
$UUID = 'AAAD56B5460339234A4A2492680171A88818B96B8D8DA687FB';
$rs = $this->domainSPushWeek->push($UUID);
$this->assertSame(0, $rs);
}
}上面是针对每周推送领域业务类的测试用例,先是清除了测试数据,然后重新进行推送,并验证返回的结果值为0。状态码为0表示成功,非0表示不同的失败原因。
每周推送领域业务类是一个具体的实现类,在这之前,我们需要实现公共推送领域业务基类。这个基类是实现扩展其他不同种类推送的关键,并且也是需要采用模板方法的设计。它维护了公共通用的流程步骤,但又允许实现子类进行定制和扩展。经过不断的努力和重构优化,并在单元测试驱动的指导下,最终此推送基类的实现代码如下:
// Family-2.0$ vim ./Apps/Scale/Domain/SPushBase.php
abstract class Domain_SPushBase {
/**
* 统一的推送模板方法
*/
public function push($UUID) {
$userId = Domain_User_Helper::UUID2UserId($UUID);
if ($userId <= 0) {
return 1;
}
$domainMotherInfo = new Domain_SMotherInfo();
$infoEx = $domainMotherInfo->getInfoEx($userId);
$infoEx['user_id'] = $userId;
if (empty($infoEx)) {
return 1;
}
//过滤不符合条件的用户
if (!$this->varidateInfo($infoEx)) {
return 2;
}
//过滤已有纪录的用户,以防重复推送
$domainPushReocrd = new Domain_SPush_Record();
if ($domainPushReocrd->hasPushBefore($userId, $this->getPushRecordType($infoEx))) {
return 3;
}
//找到绑定的称
$domainDevice = new Domain_Device_User();
$deviceList = $domainDevice->getList($userId, Model_Device::DEVICE_TYPE_SCALE);
if (empty($deviceList) || empty($deviceList[0]['binded_groups'][0]['group_id'])) {
DI()->logger->error('no device or no group for user when push week', array('userId' => $userId));
return 5;
}
$toPushWeekGroupId = $deviceList[0]['binded_groups'][0]['group_id']; //取第一个家庭组
//动态图片
$isPostFeed = $this->postFeed($userId, $infoEx, $toPushWeekGroupId);
if (!$isPostFeed) {
return 6;
}
//推送纪录
$domainPushReocrd->takeRecord($userId, $this->getPushRecordType($infoEx));
return 0;
}
}从上面的Domain_SPushBase::push($UUID)接口签名可以看出,可以针对特定的用户进行不同种类的推送。在推送的过程中,会进行一系列的检测、判断和操作,例如用户是否满足条件,是否已被推送,是否绑定了相关的称设备,进行具体的推送,最后纪录推送的情况。如果这些未能进行统一控制,而是由每个业务类重复实现,不仅会导致代码上的重复,而且也难以保持业务流程上的一致性,从而缺乏对业务规则的统一管理。
Domain_SPushBase是一个抽象类,它有两个重要的抽象方法,分别是发布动态Domain_SPushBase::postFeed($userId, $infoEx, $toPushWeekGroupId)和获取推送纪录类型Domain_SPushBase::getPushRecordType($infoEx)。在实现具体的领域业务子类时,只需要实现这两个抽象方法即可。
abstract class Domain_SPushBase {
/**
* 验证用户是否满足推送的业务要求
*/
protected function varidateInfo($infoEx) {
return true;
}
/**
* 发布动态
*/
abstract protected function postFeed($userId, $infoEx, $toPushWeekGroupId);
/**
* 推送纪录类型
*/
abstract protected function getPushRecordType($infoEx);
}注意到,在此推送基类里,还有一个可重载的方法,即验证用户是否满足推送的业务要求的类方法Domain_SPushBase::varidateInfo($infoEx),这一步是用于检测是否需要向用户进行推送。默认情况是满足条件。
认识了推送基类后,再回来看下如何在继承此基类的情况下,快速完成特定每周营养计划推送的业务逻辑。最终推送的信息,其展示效果如图6-8的设计稿所示。
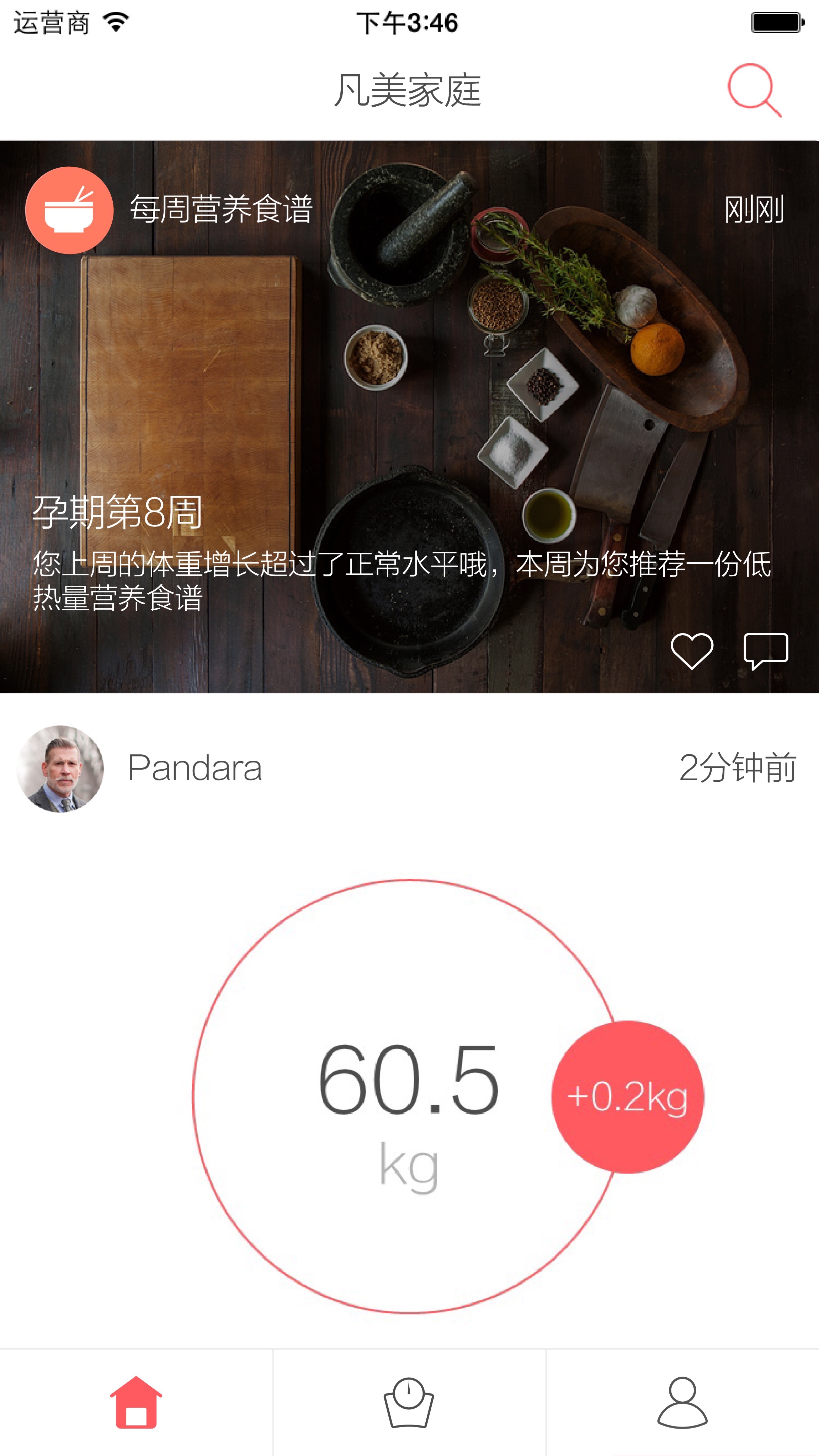
图6-8 每周营养食谱设计稿
按照基类在模板方法下定义的流程步骤,首先需要实现检测判断用户是否满足推送每周营养计划的条件。
// Family-2.0$ vim ./Apps/Scale/Domain/SPush/Week.php
<?php
class Domain_SPush_Week extends Domain_SPushBase {
/**
* 验证用户是否满足推送的业务要求
*/
protected function varidateInfo($infoEx) {
if ($infoEx['gender'] != Domain_SInfo::GENDER_FEMALE) {
return false;
}
if ($infoEx['type'] != Domain_SInfo::TYPE_PREGNANT) {
return false;
}
... ...
if ($infoEx['expect_born_date'] <= 0 || $infoEx['expect_born_date'] < $_SERVER['REQUEST_TIME']) {
return false;
}
if ($infoEx['weight_before_born'] <= 0) {
return false;
}
return true;
}
}由于推送的目标用户人群是孕妇,因此在前面判断了是否为女性,且为孕妇。中间省略部分的代码,进行了更多信息的合法性检测,避免对错误或不齐全的用户进行错误的推送。最后,还判断了预产期等数据的有效性。
接下来,就是关键的发布动态这一推送实现过程。
// Family-2.0$ vim ./Apps/Scale/Domain/SPush/Week.php
/**
* 发布动态
*/
protected function postFeed($userId, $infoEx, $toPushWeekGroupId) {
$weekth = $this->getWeekth($infoEx);
$weekCfg = DI()->config->get('push.week');
//体重与文案
$nextWeekNeedCAL = 0;
$nextWeekContent = '';
$lastWeekWeight = $this->getLastWeekWeight($userId);
if ($lastWeekWeight <= 0) {
//上周无秤重
... ...
} else {
//上周有秤重
... ...
}
//选择一个合适的食谱
$domainNutritionRecipe = new Domain_Nutrition_SRecipe();
$recipeId = $domainNutritionRecipe->extractRandomOneByCalorie($nextWeekNeedCAL);
if ($recipeId <= 0) {
return false;
}
$domainFeed = new Domain_Feed();
$postUserId = DI()->config->get('app.NPC.week_push.userId');
$typeStruct = json_encode(
array(
'content_type' => $weekCfg['content_type'],
'recipe_id' => $recipeId,
'week_num' => $weekth,
'url' => sprintf($weekCfg['jump_url'], $recipeId, $weekth),
)
);
$feedId = $domainFeed->postBaseFeed($postUserId, $toPushWeekGroupId, $nextWeekContent, 0, 0, 'web', $typeStruct);
//动态图片
if (!empty($weekCfg['pics']) && is_array($weekCfg['pics'])) {
$domainFeed->attachFeedPics($feedId, $weekCfg['pics']);
}
return true;
}上面是精简后的实现代码片段。这段代码比较有意思,因为它的过程也是有规律可循的。在最前面,先获取当前用户的周数以及相关的配置信息,随后获取用户上周的体重历史数据。根据上面的体重情况,算出CAL后,便来到了核心的部分:选择一个合适的食谱。如果这时没有合适的食谱,那么返回FALSE表示失败。如果有合适的食谱,那么就进行推送操作。这时,准备好待推送的数据后,委托给Domain_Feed动态领域业务类进行发布,并且如果有动态图片资源的话,则附上相关的图片。最终用户就可以看到类似图6-8这样的推送效果了!
Domain_SPushBase抽象蕨类有两个抽象方法,现在我们实现了其中一个,另外一个则是非常简单的。它主要的作用是用于辅助纪录对于各种推送,每个用户推送的情况,避免重复推送。因此需要一个唯一的标识来作区分。以下是每周营养计划推送中的实现代码。
// Family-2.0$ vim ./Apps/Scale/Domain/SPush/Week.php
/**
* 推送纪录类型
*/
protected function getPushRecordType($infoEx) {
return sprintf('week_%s', $this->getWeekth($infoEx));
}每周营养计划推送是固定周期的推送,让我们再来看一个触发推送的示例。例如,当准妈妈第一次使用营养称时,为了指供新人指引以及表示欢迎,可以进行一次场景推送。因为此场景推送的实现比较简单,以下是全部实现的代码片段。
// Family-2.0$ vim ./Apps/Scale/Domain/SPush/SpecialSceneWelcome.php
<?php
class Domain_SPush_SpecialSceneWelcome extends Domain_SPushBase {
protected function varidateInfo($infoEx) {
return $infoEx['type'] == Domain_SInfo::TYPE_PREGNANT;
}
protected function postFeed($userId, $infoEx, $toPushWeekGroupId) {
$specialCfg = DI()->config->get('push.special_scene.6');
$domainFeed = new Domain_Feed();
$postUserId = DI()->config->get('app.NPC.special_scene.userId');
$typeStruct = json_encode(
array(
'content_type' => 6,
'url' => $specialCfg['jump_url'],
)
);
$content = $specialCfg['content'];
$feedId = $domainFeed->postBaseFeed($postUserId, $toPushWeekGroupId, $content, 0, 0, 'web', $typeStruct);
if ($feedId > 0 && !empty($specialCfg['pics']) && is_array($specialCfg['pics'])) {
$domainFeed->attachFeedPics($feedId, $specialCfg['pics']);
}
return $feedId > 0;
}
protected function getPushRecordType($infoEx) {
return 'ss_welcome';
}
}可以看到,虽然是不同的推送实现,但其实现是类似的,特别在发布动态过程中,也是先获取配置信息,委托给Domain_Feed领域业务类进行动态的发布,最后返回是否成功推送的布尔值。这样既有利于不同功能的快速开发,因为可以重用通用的功能,又可以达到风险隔离、封装变化,即各个业务线独立变化,互不干扰。我觉得,这是一种好的设计,而且事实上它也工作得非常好。
6.5.3 如何测试耗时的计划任务
在本小节中,我们先是研究了如何收集用户上报的体重数据,接着学习了如何使用模板方法设计模式进行不同场景下的推送操作。现在,我们有了体重这一基础数据,也实现了推送功能。那么,接下来的问题是,我们该如何调度执行这些推送操作呢?显然,推送有两大类,一类是定时的推送,如每日、每周、每月推送;一类是触发的推送,如欢迎新用户。既然推送的时机随时都有可能发生,而且是属于耗时的操作,更为重要的是,不管用户是否上线使用App,都应该能为其进行推送。因此,一个不错的方案就是通过后台异步的计划任务对推送进行调度。如前面所述,我们使用了Task计划任务扩展类库。假设Task已经安装部署完毕,下面重点来看下如何实现具体的调度业务。
在开始编写计划任务之前,有一些事情是需要明确的。提前考虑到这些问题,可以避免错误的设计,同时提高开发的效率。首先,,调用上面开发好的推送接口,是通过远程接口服务调度,还是直接本地调度?其次,也是比较关键的问题,就是待消费的MQ数据从哪里来,又存在哪里?
上面第一个问题,比较容易解决,把计划任务的接口服务放在我们上面所说的Task项目中,并且通过本地的方式进行调度。因此也就不需要对外提供访问入口。注意这里的Task项目目录不是指扩展类库的Task目录。剩下第二个问题,则需要一步步编写代码实现了。例如,对于每周营养计划的推送,首先要从数据库的用户表中筛选出候选用户,然后可以把候选用户放进内存数组MQ中,最后进行消费。
Task扩展类库有一个通用的触发器,但基于我们现在特定的业务场景,由于已经可以确定使用本地调度、内存数组MQ和特定的接口服务,所以可以自定义实现更能与当前业务场景的触发器。
// Family-2.0$ vim ./Apps/Task/TMyTrigger/PushBase.php
<?php
abstract class TMyTrigger_PushBase implements Task_Progress_Trigger {
public function fire($params) {
//取全部待推送的用户
$suser = $this->getWaitTOPushUserORM();
$mq = new Task_MQ_Array();
$runner = new Task_Runner_Local($mq);
$service = $this->getService();
$num = 0;
while (($row = $suser->fetch())) {
$num ++;
$UUID = Domain_User_Helper::userId2UUID($row['user_id']);
$mq->add($service, array('other_UUID' => $UUID, 'app_key' => '***', 'sign' => '***'));
$rs = $runner->go($service);
}
return $num;
}
/**
* 取全部待推送的用户
* @return NotORM
*/
abstract protected function getWaitTOPushUserORM();
/**
* 取服务名称
*/
abstract protected function getService();
}上面是一个抽象触发器基类,它封装了具体的调度过程。具体实现子类只需要实现获取全部待推送的用户,以及获取服务名称这两个抽象方法即可。
下面是每周营养推送的具体实现。主要是实现了筛选初步符合每周推送的用户, 以及指定待执行的接口服务名称。
// Family-2.0$ vim ./Apps/Task/TMyTrigger/WeekPush.php
<?php
class TMyTrigger_WeekPush extends TMyTrigger_PushBase {
protected function getWaitTOPushUserORM() {
return DI()->notorm->suser
->select('user_id')
->where('type', 1)
->where('height > ?', 0)
->where('weight > ?', 0);
}
protected function getService() {
return 'Nutrition_SWeek.Push';
}
}这里待执行的接口服务是Nutrition_SWeek.Push,那这个接口服务又在哪呢?还记得前面实现的每周推送领域业务类Domain_SPush_Week吗?其实此接口服务就是Domain_SPush_Week对应的上层接口类。打开这个接口类的文件,可以看到它需要一个other_UUID必须参数,以及在实现时调用了Domain_SPush_Week领域业务类。正如我们所预料的那样。以下是相应的代码片段。
// Family-2.0$ vim ./Apps/Scale/Api/Nutrition/SWeek.php
<?php
class Api_Nutrition_SWeek extends PhalApi_Api {
public function getRules() {
return array(
'*' => array(
'otherUUID' => array('name' => 'other_UUID', 'require' => true, 'min' => 50, 'max' => 50,),
),
);
}
public function push() {
$rs = array('code' => Common_Def::CODE_OK, 'msg' => '');
$domain = new Domain_SPush_Week();
$rs['code'] = $domain->push($this->otherUUID);
return $rs;
}
}至此,就可以把整个业务流程打通了。那就是说,到此为止,我们已经初步实现了母婴营养称中核心的业务功能。也许这时,你可能觉得已经完成了重要的业务功能,可以暂且休息或者请年假出去旅游了。但也正如你看见的,从用户上报体重数据,到最后推送营养计划,这个过程涉及的业务众多,流程链路长,那么我们如何保证整个系统的稳定性和正确性呢?一个毫无疑问的回答是,单元测试。前面没有过多介绍单元测试,并不是暗示在这里不需要单元测试。恰恰相反,这里更需要单元测试,特别对于计划任务。没有介绍单元测试,是因为避免过多分散读者的注意力,并且已经假设读者对单元测试已经能熟悉应用。
但对于耗时的计划任务又应该如何快速测试呢?在测试时,并不能每次都对全部的用户进行推送。假设推送一次需要1秒,那么推送1200个用户,就需要20分钟。每次执行单元测试都需要20分钟,那简直是在浪费程序员的时间!还记得我们的F.I.R.S.T原则吗?其中一个原则就是要快速。因此,哪怕是进行计划任务的单元测试,我们也要保证它的快速性。对此,我曾有切身的体会。在我曾经刚入职的时候,有一项开发任务就是修改某个计划任务,追加对某个字段的处理。需求很简单,我也很快就修改好了。但由于当时的项目没有单元测试,本地也无法进行自测,需要提交代码并发布到回归环境后方能验证。你知道,人总会有犯错的时候。我第一次修改的代码有问题,得到测试人员的反馈后我进行了调整。再次提交代码,发布到回归环境,并经过漫长的等待(等待计划任务执行到我所编写修改的代码区域)后,被再次告知我遗漏了另一外的修改,那时已经等待了一个多小时……就这样,往来多次调整修改,因为反馈周期长,导致最终项目发布延迟。QA负责人都已经不耐烦地大叫道:“谁改的代码?怎么还不行?!”。如果你是那时的我,肯定会这么想:“要是有立即反馈的单元测试就好了”。而要想针对计划任务编写快速反馈的单元测试,需要掌握一些技巧。
首先,我们要保证单个执行过程的正确性。在上面的每周营养计划推送的场景中,单个执行过程其实就是指Nutrition_SWeek.Push接口服务在业务上的正确性。对于接口类的测试,我们前面已经介绍,这里不再赘述。关键是对计划任务调度过程的验证,也就是第二个重要的技巧。如果前面对一个用户进行推送这单个执行过程是正确的,并得到了充分的测试和验证,那么我们就有理由相信,对于10个、100个、乃至100万个用户进行推送都是能正常工作的。因此,在验证计划任务调度的过程时,我们可以把具体的执行过程进行模拟,不是真正进行推送操作,而是模拟推送。这样,便可大大减少执行的时间,提高单元测试反馈的速度。此外,只需关注对调度过程的验证即可。
例如,对于每周营养计划的触发器类,可以通过重载方法指定一个模拟的接口服务,从而达到模拟单个执行过程的目的。可先定义一个模板的推送接口服务,它什么都不做,只是返回一个模板的结果,如:
class Api_Nutrition_Mock extends PhalAPi_Api {
public function push() {
return array('code' => Common_Def::CODE_OK, 'msg' => '');
}
}随后,在继承TMyTrigger_WeekPush的子类中,返回该模板的接口服务名称,如:
class TMyTrigger_WeekPush_Mock extends TMyTrigger_WeekPush {
protected function getService() {
return 'Nutrition_Mock.Push';
}
}最后,在进行单元测试时,便可利用此模拟的触发器类的对象进行测试验证,而不用再担心会存在耗时的执行过程,更不用担心会有什么副作用(在测试时向用户进行推送,而造成骚扰),因为一切都是模拟的。下面是使用替身进行测试的代码片段。
class PhpUnderControl_TaskMyTriggerWeekPush_Test extends PHPUnit_Framework_TestCase
{
public $taskMyTriggerWeekPush;
protected function setUp()
{
parent::setUp();
$this->taskMyTriggerWeekPush = new TMyTrigger_WeekPush_Mock();
}
/**
* @group testFire
*/
public function testFire()
{
$params = '';
$rs = $this->taskMyTriggerWeekPush->fire($params);
$this->assertGreaterThan(0, $rs);
}
}最后,小结一下。在开发接口服务的过程中,你会发现,很多时候都是像这里的案例一样,开发环节是一环扣一环,环环相扣的。如果前面设计不合理,就会导致后面也跟着错误的实现。通常情况下,会定义基础的业务数据,明确需要哪些类型的数据。在对实体的属性有了一定了解后,便可以基于业务需求和规则开发相应的接口服务。这些接口服务运行一段时间后,会产生上述基础业务数据。而这些基础数据又会催生更多的数据,例如对每周的体重进行分析从而给出营养周报和计划。这时,除了需要实现第二批接口服务外,对于耗时的接口服务的调度还要辅以计划任务来管理。好的框架应该能支持这些功能的开发,但我觉得,更为重要的是,框架应该引导开发人员进行这样有序的开发。即能在原来的基础上,进行迭代开发,新的功能与原有的功能可以很好的一起工作,相互促进。每当在项目中添加一个类,这个新的类都是以帮助系统中的其他类为目的的,而不是以干扰、抑制甚至破坏其他类为目的。不管这是有意识的,还是无意识的。PhalApi框架,我认为,很好地做到了这一点:引导软件开发工程师进行有序地开发。
6.5 精益求精
古人有云:业精于勤而荒于嬉。
但对于软件开发工程师来说,要想做到精益求精,不仅需要勤奋努力,我觉得适当有效地运用工具,也是必不可少的。下面,我们将在学习一下,在使用PhalApi完成项目开发后,可以使用哪些工具来帮助我们更好地进行开发,部署、发布和性能优化。
6.5.1 获取家庭圈信息的接口服务
为了更好地理解如何使用接下来要介绍的工具,并应用在实际项目开发过程中,先来简单认识一个接口服务——获取家庭圈信息。
在Family 2.0 项目中,有一个重要的业务模块,即家庭圈。家庭圈对应的数据库表为fami_group,它的部分表结构定义如下:
CREATE TABLE `fami_group` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`number` varchar(10) DEFAULT '0000' COMMENT '家庭号',
`groupname` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT '' COMMENT '家庭组名称',
`password` varchar(64) DEFAULT '' COMMENT '密码',
... ...
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;并且,假设已经在以下测试数据,它的家庭号为8888,家庭圈名称为“我的家”,密码为1234。
表6-3 家庭表fami_group的测试数据
| id | number | groupname | password |
|---|---|---|---|
| 1 | 8888 | 我的家 | 1234 |
现在,需要开发一个获取家庭圈信息的接口服务,并使用此接口服务中获取上面ID为1的信息,结合单元测试驱动开发以及前面所学的知识,我们很快就能编写出下面这样的代码。
Api接口层为:
// Family-2.0$ vim ./Apps/Fami/Api/Group.php
<?php
class Api_Group extends PhalApi_Api {
public function getRules() {
return array(
'getGroupInfo' => array(
'groupId' => array('name' => 'group_id', 'require' => true),
),
);
}
public function getGroupInfo() {
$rs = array('code' => Common_Def::CODE_OK, 'msg' => '');
$domain = new Domain_Group();
$rs['info'] = $domain->getGroupInfoByGroupId($this->groupId);
return $rs;
}
}Domain领域业务层为:
// Family-2.0$ vim ./Apps/Fami/Domain/Group.php
<?php
class Domain_Group {
public function getGroupInfoByGroupId($groupId) {
$model = new Model_Group();
$row = $model->getGroupInfoByGroupId($groupId);
return $row;
}
}最后,Model数据模型层为:
// Family-2.0$ vim ./Apps/Fami/Model/Group.php
<?php
class Model_Group extends PhalApi_Model_NotORM {
public function getGroupInfoByGroupId($groupId) {
return $this->getORM()
->select('number, groupname, password')
->where('id', $groupId)
->fetchRow();
}
}开发完成后,可以在浏览器或者通过curl命令简单测试一下,验证获取信息是否正确。如:
$ curl "http://api.v2.family.com/fami/?service=Group.getGroupInfo&group_id=1"正常情况下,会返回类似以下这样的结果:
{
"ret": 200,
"data": {
"code": 0,
"msg": "",
"info": {
"number": "8888",
"groupname": "我的家",
"password": "1234"
}
},
"msg": ""
}至此,又一功能性的需求已经开发完成。但对于非功能性的需求呢?例如,Group.getGroupInfo这一接口的响应时间如何?支持最大并发量是多少?
6.5.2 使用Xhprof剖析性能
Xhprof是一个非常优秀的性能分析工具,它可以从程序内部剖析代码执行过程中每个环节的具体情况。这里不过多的讲述此工具的特点和使用,而讲述如何使用Xhprof发现系统中的性能瓶颈。
假设Xhprof扩展已安装成功。使用以下命令可检测本地环境是否已开启了xhprof扩展,正常情况下可以看到输出xhprof。
$ php -m | grep xhprof
xhprof环境准备就绪后,为了使用xhprof,可修改对应的入口文件,在index.php文件前后分别加上xhprof相应的代码片段。如:
// Family-2.0$ vim ./Public/fami/index.php
<?php
// start profiling
xhprof_enable();
require_once dirname(__FILE__) . '/../init.php';
//装载你的接口
DI()->loader->addDirs('Apps/Fami');
/** ---------------- 响应接口请求 ---------------- **/
$api = new PhalApi();
$rs = $api->response();
$rs->output();
// stop profiler
$xhprof_data = xhprof_disable();
$XHPROF_ROOT = '/path/to/xhprof';
include_once $XHPROF_ROOT . "/xhprof_lib/utils/xhprof_lib.php";
include_once $XHPROF_ROOT . "/xhprof_lib/utils/xhprof_runs.php";
// save raw data for this profiler run using default
// implementation of iXHProfRuns.
$xhprof_runs = new XHProfRuns_Default();
// save the run under a namespace "xhprof_foo"
$run_id = $xhprof_runs->save_run($xhprof_data, "xhprof_foo");
echo "http://<xhprof-ui-address>/index.php?run=$run_id&source=xhprof_foo\n";此时,再次调用Group.getGroupInfo接口服务并获取group_id为1的家庭圈信息时,根据生成的报告$run_id及配置的站点环境,便可在浏览器在线查看到对应的性能分析报告。在这里,按”Excl. Wall Time“字段降序排列后,可看到类似以下这样的报告。
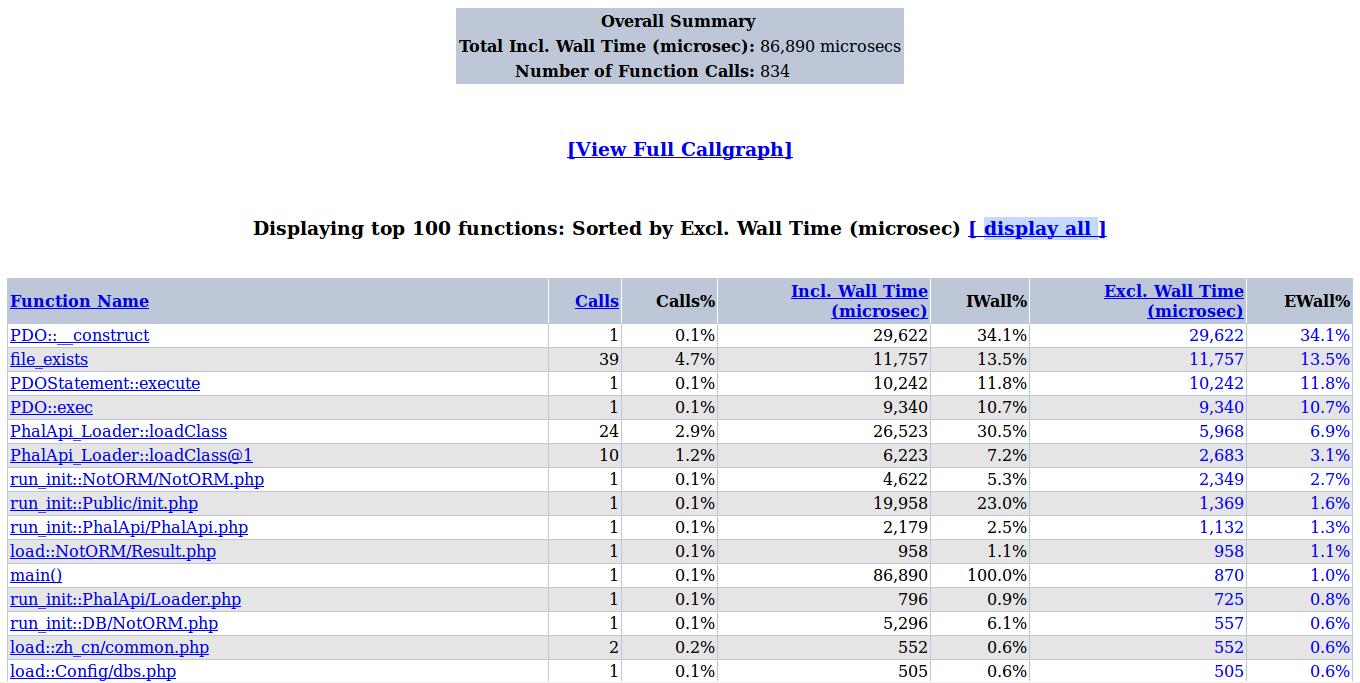
图6-9 无缓存下的性能分析报告
从上图可以看出,耗时最严重的前4个操作中,就有3个操作是与数据库访问有关的,分别是:PDO::__construct,PDOStatement::execute、和PDO::exec。这三个操作加起来的执行时间已经占据了整体的约56.6%,由此可见数据库的访问耗时之多。
Xhprof还提供了可视化的图形,并对耗时最多的环节标为红色,用黄色标记了耗时最多的执行过程。例如,上面对应的完整的调用图表为:
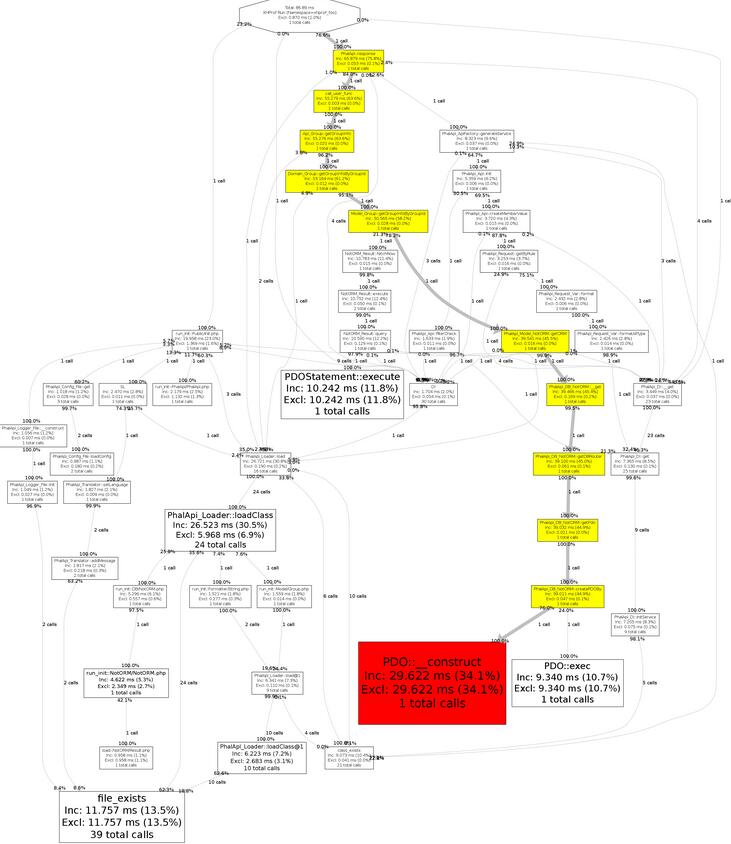
图6-10 获取家庭圈信息接口服务的完整的调用图表
在书本上,图6-10可能查看起来不方便,但大家暂时不必扣于细节,只需要对Xhprof提供的图表有个感性的认识即可。具体的图表,可根据自己项目的情况,生成对应的分析报告再细细研究。从中,我们也看到了,使用PDO连接访问数据库这一链路,耗时最大。下面是对耗时最严重的环节,放大后的局部图表。
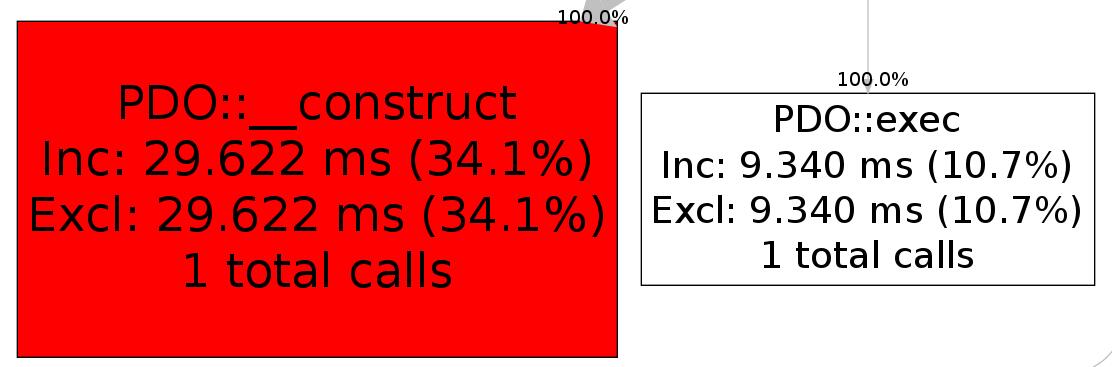
图6-11 耗时的PDO操作
Xhprof工具,通常在开发过程中使用,也就是说,应该在开发环境中使用。结合Xhprof性能分析的报告和图表,从整体到局部,可找到系统中的瓶颈所在,避免进行不必要的优化。可以说Xhprof是一种白盒性能测试,因为它需要知道源代码的实现和执行过程。关于Xhprof的介绍,暂时先到这,但在实际项目开发过程中,你应该有意识地使用该工具对所开发的项目系统进行性能分析。此外,对于获取家庭圈信息接口的性能优化,下面会继续讲到。
6.5.3 Autobench压力测试与高效缓存
在优化获取家庭圈信息接口的性能之前,让我们再来认识另一个强大的工具——Autobench。Autobench是一款基于httperf的Perl脚本,可用于Web性能测试和压力测试。在这一小节中,我们来看下如何使用Autobench发现性能瓶颈,以及如何使用高效缓存提升系统的响应时间和吐吞量。
Autobench与Xhprof有所区别,前者更多是应用在生产环境,通常是测试人员用来对生产环境上的系统进行压力测试时必不可少的工具,而Xhprof只是应用在开发环境。另一个区别是,Xhprof是白盒性能测试,而Autobench则是黑盒性能测试,它不关注内部代码的具体实现的执行过程,而是从外部用户访问和使用的角度来分析系统的性能情况。
对无缓存的接口服务进行压测
假设Autobench已经安装成功,并且所依赖的httperf、gawk、gnuplot等均已安装完毕。为了方便进行压力测试,先准备一个基础的shell脚本./sh/autobench.sh,其实现代码如下:
#!/bin/bash
if [ $# -eq 0 ]; then
echo "Usage: $0 <host> <uri>"
echo ""
exit
fi
DM=$1
URL=$2
#--signle_host 只测单机
#--host1 测试主机地址
#--uri1 host1 测试URI
#--quiet 安静模式
#--low_rate 测试时最低请求数(指 httperf)
#--hight_rate 测试时最高请求数
#--rate_step 每次测试请求数增加步长
#--num-call 每连接中发起联接数,一般是1
#--num_conn 测试联接数
#--file 测试结果输出的 tsv文件
autobench \
--single_host \
--host1=$DM \
--port1=80 \
--uri1=$URL \
--low_rate=1 \
--high_rate=50 \
--rate_step=1 \
--num_call=1 \
--num_conn=50 \
--timeout=5 \
--file ./$DM.tsv其中,比较关键的参数是测试时最低请求数--low_rate,测试时最高请求数--hight_rate,以及每次测试请求数增加步长--rate_step。这些参数可根据实际情况进行调整,如这里是最低请求数为1,最高请求数为50,每次增加的步长为1。赋予执行权限后,便可以执行此脚本进行压力测试,它的第一个参数是待压测的域名,在这里是api.v2.family.com,第二个参数是待压测的访求路径及参数,这里是上面所开发的接口服务Group.getGroupInfo。
执行以下命令,便可以开始进行压测。
Family-2.0$ cd sh/
sh$ ./autobench.sh api.v2.family.com "/fami/?service=Group.getGroupInfo&group_id=1"压测期间,可以看到类似这样的状态信息:
Reply rate [replies/s]: min 0.0 avg 0.0 max 0.0 stddev 0.0 (0 samples)
Reply time [ms]: response 323.8 transfer 0.0
Reply size [B]: header 214.0 content 123.0 footer 2.0 (total 339.0)
Reply status: 1xx=0 2xx=50 3xx=0 4xx=0 5xx=0最后,压测完毕后可以看到生成的压测报告数据,保存在./sh/api.v2.family.com.tsv文件中。里面的有各项指标的数据,类似如下:
dem_req_rate req_rate_api.v2.family.com con_rate_api.v2.family.com min_rep_rate_api.v2.family.com avg_rep_rate_api.v2.family.com max_rep_rate_api.v2.family.com stddev_rep_rate_api.v2.family.com resp_time_api.v2.family.com net_io_api.v2.family.com errors_api.v2.family.com
1 1.0 1.0 1.0 1.0 1.0 0.0 81.2 0.4 0
2 2.0 2.0 2.0 2.0 2.0 0.0 77.7 0.9 0
3 3.0 3.0 3.0 3.0 3.0 0.0 75.8 1.3 0
... ...
41 32.9 32.9 0.0 0.0 0.0 0.0 298.1 14.5 0
42 33.0 33.0 0.0 0.0 0.0 0.0 311.3 14.5 0
43 32.8 32.8 0.0 0.0 0.0 0.0 333.2 14.4 0
... ...
48 15.3 15.3 0.0 0.0 0.0 0.0 1046.8 6.7 0
49 13.6 13.6 0.0 0.0 0.0 0.0 1268.8 6.0 0
50 14.6 14.6 0.0 0.0 0.0 0.0 953.7 6.4 0为了更方便浏览这份报告数据,可以执行以下命令,生成对应的可视化图表。
sh$ bench2graph ./api.v2.family.com.tsv ./api.v2.family.com_1_50_without_cache.png生成的图表如下所示。
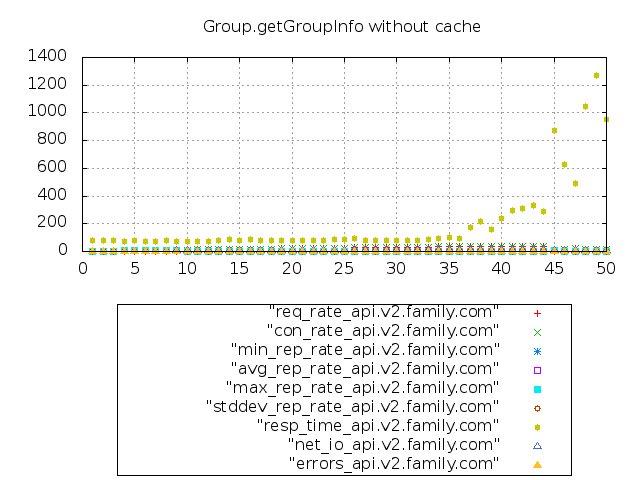
图6-12 无缓存下的压测情况
结合数据报告及可视化的图表,不难发现,在没有使用缓存直接访问数据库的情况下,当请求量在35 QPS以下时,平均响应时间约为81毫秒。但当请求量达到近50 QPS时,响应时间急剧上升到了近1秒。这意味着,当有50个以上客户端同时访问Group.getGroupInfo这个接口服务时,响应时间需要1秒以上。
那有没有可以优化的办法呢?答案是肯定的。
使用高效缓存优化响应时间
这里主要的性能瓶颈在于对数据库的访问(关于如何发现系统中的性能瓶颈,下一节会介绍Xhprof工具),因此可以使用高效缓存来对从远程数据库获取的家庭圈信息进行缓存。假设,例如的是Memcache,调整后的Model层代码如下:
// Family-2.0$ vim ./Apps/Fami/Model/Group.php
<?php
class Model_Group extends PhalApi_Model_NotORM {
public function getGroupInfoByGroupId($groupId) {
//return $this->getORM()
// ->select('number, groupname, password')
// ->where('id', $groupId)
// ->fetchRow();
$key = 'group_info_' . $groupId;
$data = DI()->cache->get($key);
if (!empty($data)) {
return $data;
}
$data = $this->getORM()
->select('number, groupname, password')
->where('id', $groupId)
->fetchRow();
DI()->cache->set($key, $data, 600);
return $data;
}
}新的Model实现中,先从Memcache缓存中尝试获取缓存的家庭圈信息,如果有缓存则直接返回。没有缓存,再尝试从数据库中获取,从而大大降低减少了对数据库的耗时操作。
保存代码后,重新进行同样的压力测试,可以看到新的压力测试报告数据类似如下:
dem_req_rate req_rate_api.v2.family.com con_rate_api.v2.family.com min_rep_rate_api.v2.family.com avg_rep_rate_api.v2.family.com max_rep_rate_api.v2.family.com stddev_rep_rate_api.v2.family.com resp_time_api.v2.family.com net_io_api.v2.family.com errors_api.v2.family.com
1 1.0 1.0 1.0 1.0 1.0 0.0 33.7 0.4 0
2 2.0 2.0 2.0 2.0 2.0 0.0 29.4 0.9 0
3 3.1 3.1 3.0 3.0 3.0 0.0 28.5 1.3 0
... ...
41 36.6 36.6 0.0 0.0 0.0 0.0 204.3 16.1 0
42 37.7 37.7 0.0 0.0 0.0 0.0 189.9 16.6 0
43 36.4 36.4 0.0 0.0 0.0 0.0 249.1 16.0 0
... ...
48 36.6 36.6 0.0 0.0 0.0 0.0 307.4 16.1 0
49 36.6 36.6 0.0 0.0 0.0 0.0 323.8 16.1 0
50 36.1 36.1 0.0 0.0 0.0 0.0 343.2 15.9 0对应的可视化报表为:
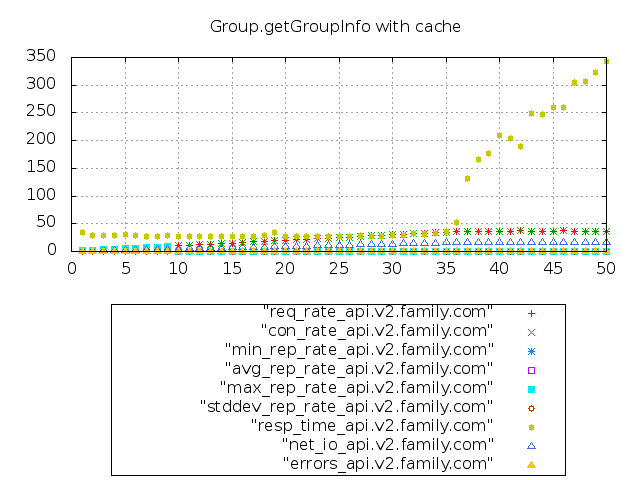
图6-13 使用缓存的压测情况
再次结合报告数据和可视化图表,不难发现,当请求量在35 QPS以下时,接口服务的平均响应约为29毫秒。当请求量接近50 QPS时,响应时间才上升到约340毫秒。
考虑到数据较多,我们抽取使用缓存前后部分的报告数据进行对比,分别取每秒请求量为5、10、15、……、50时的响应时间,对比并统计如下。
表6-4 使用高效缓存优化前后的响应时间对比
| 每秒请求量 | 未使用缓存的响应时间(ms) | 使用高效缓存的响应时间(ms) | 响应时间降低比率 |
|---|---|---|---|
| 5 | 77.7 | 29.8 | 61.65% |
| 10 | 75.5 | 27.8 | 63.18% |
| 15 | 82.9 | 27.9 | 66.34% |
| 20 | 81.8 | 27.7 | 66.14% |
| 25 | 83.8 | 27.9 | 66.71% |
| 30 | 79.2 | 28.2 | 64.39% |
| 35 | 100.9 | 35.9 | 64.42% |
| 40 | 240.4 | 209.6 | 12.81% |
| 45 | 874.8 | 259 | 70.39% |
| 50 | 953.7 | 343.2 | 64.01% |
很明显,使用高效缓存显著提升了接口服务的响应时间,比原来平均减少了约56%和响应时间。上面压测数据根据不同的服务器环境,最终得到的结果也不尽相同。但可以肯定的是,使用本地高效缓存代替远程数据库访问,确实能够大大降低系统的响应时间,优化性能。
6.5.3 通过Phing进行版本的发布与回滚
从在本地环境完成接口服务的开发,到最后在线上真实环境接口服务的运行,中间还有一个非常重要的环节。那就是发布。团队会因规模不同、项目性质不同、企业流程不同,而采用不同的发布流程。有的是直接通过FTP进行文件上传,有的是使用自主构建的发布脚本。无论如何,都应该走自动化发布流程,避免人工地打包、上传、解压、改生产配置这些重复性的人工操作。
在自动化发布中,Phing是个不错的选择。
对于发布流程,典型的操作应包括:
- 1、备份当前代码
- 2、从代码版本管理系统中签出最新的发布代码
- 3、进行代码发布,替换原有的代码
- 4、清理工作
对应的XML配置文件,可参考:
<!-- Family-2.0$ vim ./build.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<!-- ============================================ -->
<!-- Target: build -->
<!-- ============================================ -->
<target name="build" depends="prepare,gitpull,backup,cleanup">
<copy todir="." overwrite="true" >
<fileset dir="${git_todir}">
<include name="**/**" />
<exclude name="./.git" />
<exclude name="./.git/**" />
</fileset>
</copy>
</target>
</project>基中,prepare任务主要是进行一些前期的准备,如创建临时目录。gitpull则是从Git仓库拉好最新的发布版本代码,即:
<property
name="git_todir"
value="/path/to/publish/api.v2.family.com"
override="true" />
<resolvepath propertyName="repo.dir.resolved" file="${git_todir}" />
<!-- ============================================ -->
<!-- Target: git pull -->
<!-- ============================================ -->
<target name="gitpull">
<gitpull
repository="${repo.dir.resolved}" all="true" />
</target>backup任务是对当前线上版本的代码进行备份,以便发生异常时及时回滚到上一个版本。在备份的同时,可以根据项目的情况删除历史的备份,减少服务器的硬盘空间负担。最后的cleanup任务是用于清理前期prepare任务中所创建的临时目录和文件。
在build.xml文件配置好发布的流程后,便可以进行发布操作了。但在发布前,很有必要先准备好回滚操作的配置。回滚操作比较简单,只需要切换到最后一个备份的版本即可,例如这里的:
<!-- Family-2.0$ vim ./rollback.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<project name="api.v2.family.com" default="rollback">
<property
name="backup_path"
value="/path/to/backup/api.v2.family.com"
override="true" />
<property
name="backup_prefix"
value="api.v2.family.com_phing_backup_"
override="true" />
<!-- ============================================ -->
<!-- Target: rollback -->
<!-- ============================================ -->
<target name="rollback" >
<unzip file="${backup_path}/${backup_prefix}lastest.zip" todir="." >
<fileset dir=".">
<include name="*.zip"/>
</fileset>
</unzip>
</target>
</project>有了发布与回滚这两手准备后,便可以放心进行一键发布了!
6.6 成果回顾
本章介绍了对历史遗留项目Family进行重写的开发过程,在前期进行必要的数据库迁移以及对已有的接口系统进行剖析后,我们设计了新的接口系统。重新设计的接口系统更为规范,我们不仅定义了客户端的接入规范,还约定了服务端的开发规范。此外,在新的接口系统,可以为不同的终端、不同的业务提供多个入口,划分后的多模块更有利于子系统的各自演变。而通过系统变量维护服务器配置,可以在不改动代码的情况下,实现不同环境的配置与部署。最后选择合适的扩展类库,大大减少了项目开发的周期,使得开发人员可以专注于项目业务的开发。
在重写既有的接口服务过程中,对于原来数据量大的数据库表,在新系统中采用了分表策略,从而使得横向扩容更为容易。至于代码层面,应对错综复杂的“万能类”一个有效而实用的工具就是使用特征草图。通过特征草图可以快速洞悉原来的调用依赖关系,再结合提取子类、提取子函数等重构方法便可以得到职责更为明确的设计和实现。如果面对的是更大范围的代码,则可以根据ADM分层模式进行划分,再逐层击破。
在开发新增的接口服务中,我们也遇到了不少有一定挑战性的问题。首先是对上报的体重数据的分表存储,并为这一基础业务数据开始相应的接口服务。对于复杂的领域业务,我们使用了模板方法设计模式出色地完成了推送功能,并由此产生了衍生的业务数据。为了保障计划任务的正确性,以及获得即时快速的反馈,在对耗时的计划任务进行单元测试时,可使用模拟、替身、桩等,从而大大减少不必要的等待时间。
最后,完成项目代码的编写后,我们还学习了一些在项目中经常用到或者说是非常有帮助的工具。这些工具有:用于开发环境中剖析内部执行性能的Xhprof、对生产环境系统进行压力测试的Autobench,以及可以进行发布和回滚的Phing。它们都是高级程序员手上必不可少的工具。
可以说,相比于前面的创业项目,在此重写历史遗留项目中,我们不再重点关注某个类的代码应该如何编写,而是从项目的维度考虑和分析,如何才能更有效地进行项目开发、维护和交付。希望通过这个项目,能给大家带来一定的启发性。






